GaussDB
1. GaussDB概述
1.1 国产数据库的发展
国产数据库的发展经历了从 “跟跑” 到 “并跑” 的关键跨越。早期,国内市场长期被 Oracle、MySQL 等国外产品主导,国产数据库面临技术积累薄弱、生态不完善等挑战。但近年来,随着国家对信息技术自主可控的重视,以及数字化转型需求的爆发,国产数据库迎来黄金发展期。例如:华为 GaussDB、阿里云 PolarDB 等产品通过技术创新,在分布式架构、性能优化等方面取得突破,逐步替代国外产品。
根据行业报告,2024 年中国分布式事务数据库市场规模同比增长 18.5%,其中本地部署市场占比近 40%,国产数据库在金融、政府等关键领域的渗透率显著提升。
未来,国产数据库的前景更加广阔。一方面,国家政策持续加码,如 “十四五” 规划明确提出要突破数据库等基础软件核心技术,为国产替代提供政策保障;另一方面,技术上的持续创新(如云原生、AI 融合)和生态完善(如 openGauss 开源社区装机量超10万套),使得国产数据库在性能、安全、易用性上已接近甚至超越国际竞品。预计到 2025 年,分布式数据库市场将全面爆发,国产数据库在金融、能源等行业的核心系统替换中将占据主导地位。
1.2 GaussDB介绍
GaussDB是华为自主研发的企业级分布式关系数据库,主打高性能、高可靠、强兼容,适合处理海量数据和高并发场景(比如银行、电信、政务等系统)。
GaussDB包含多个版本的数据库家族:
-
GaussDB (for openGauss)
主打政企核心业务,支持分布式事务和异地待备,已通过金融行业最高安全认证(CC EAL4+)。
-
GaussDB (for MySQL)
兼容 MySQL 生态,采用存算分离架构,最高支持 128TB 存储和百万级 QPS 吞吐,适合互联网和电商场景。
-
GaussDB (DWS)
云原生数据仓库,支持 PB 级数据实时分析,在金融行业打造了全球最大数仓集群,性能领先国际竞品。
GaussDB 的发展历程与现状
- 技术积累(2001-2019):华为自 2001 年开始研发数据库,早期聚焦通信领域嵌入式数据库,逐步拓展至内存数据库、分析型数据库。2019 年,基于 openGauss 开源社区推出 GaussDB 系列,开启企业级市场征程。
- 规模化商用(2020-2023):在金融行业实现突破,邮储银行、工商银行等国有大行核心系统成功替换,同时拓展至政府、能源、交通等领域。2022 年,GaussDB 在国内分布式数据库市场份额进入前三,金融级市场占有率第一。
- 全球化布局(2024 至今):推出 GaussDB 泰国先锋计划,在拉美、亚太地区落地医疗、电信等行业案例。海外项目超 10 个,如巴西最大医疗信息公司 MV 通过 GaussDB 实现业务效率提升,资源成本降低 25%。
- 截至 2025 年,GaussDB 已服务超过 2500 家大型企业,支撑华为 MetaERP 系统、终端云等内部核心业务,同时在全球范围内构建起覆盖咨询、迁移、运维的全生命周期服务体系,成为国产数据库走向世界的标杆。
GaussDB 的核心优势:
- 快且能扩展 用分布式架构,数据分散到多台机器处理,轻松应对数据增长,性能不卡顿。
- 兼容主流数据库 高度兼容 MySQL、PostgreSQL 等,旧系统迁移改造成本低。
- 金融级高可靠 数据多副本存储,故障自动切换,支持“两地三中心”容灾,金融级安全。例如,邮储银行新一代核心系统采用 GaussDB 后,日均处理 20 亿笔交易,峰值性能达 6.7 万笔 / 秒,响应时延降低 30%
- 安全与合规 国内首个获得 CC EAL4 + 认证的数据库,支持全密态数据保护,通过防篡改、不可抵赖等 28 项安全能力评测。同时满足金融、政务等行业的国产化替代要求
- 国产化适配 适配国产芯片、操作系统,满足信创需求。
2. 环境准备
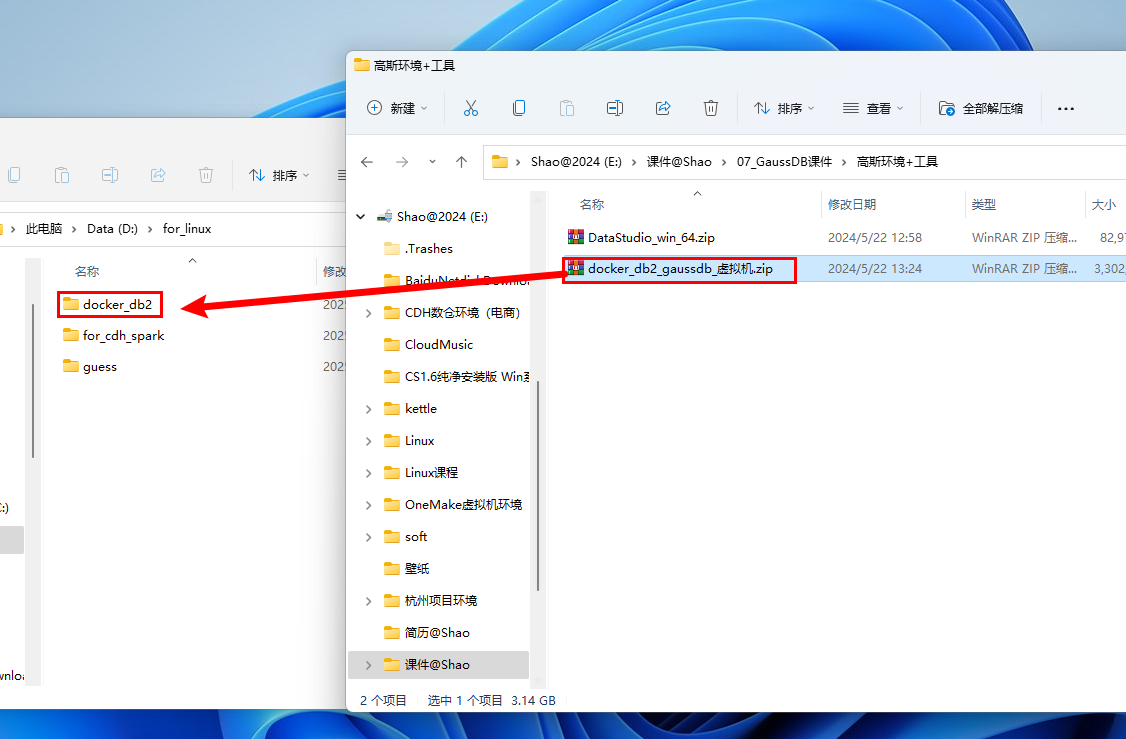
从”资料”中找到提供的虚拟机,按照以下步骤操作:
步骤1:解压 docker_db2_gaussdb_虚拟机.zip 到指定目录下
步骤2:通过 VMware 虚拟化工具,打开 GaussDB 虚拟机
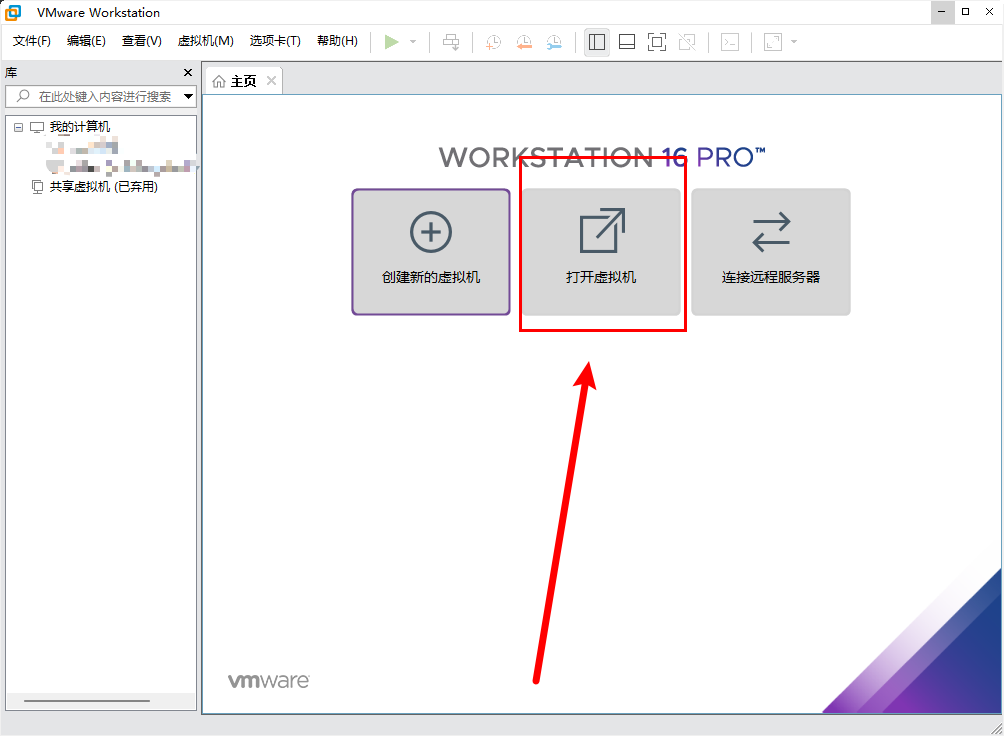
步骤3:找到自己的解压的路径,选择 docker_db2.vmx 并点击打开:
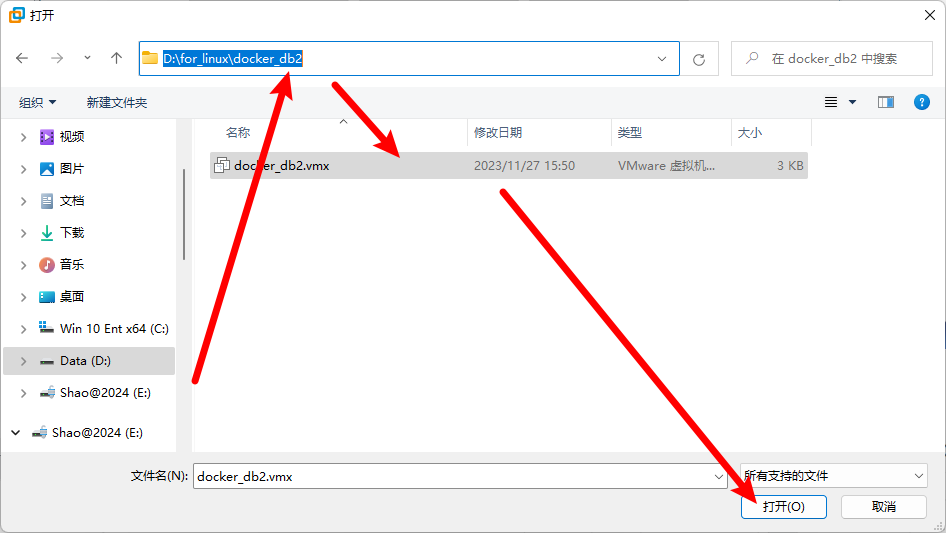
步骤4:虚拟机加载后选择”开启此虚拟机”
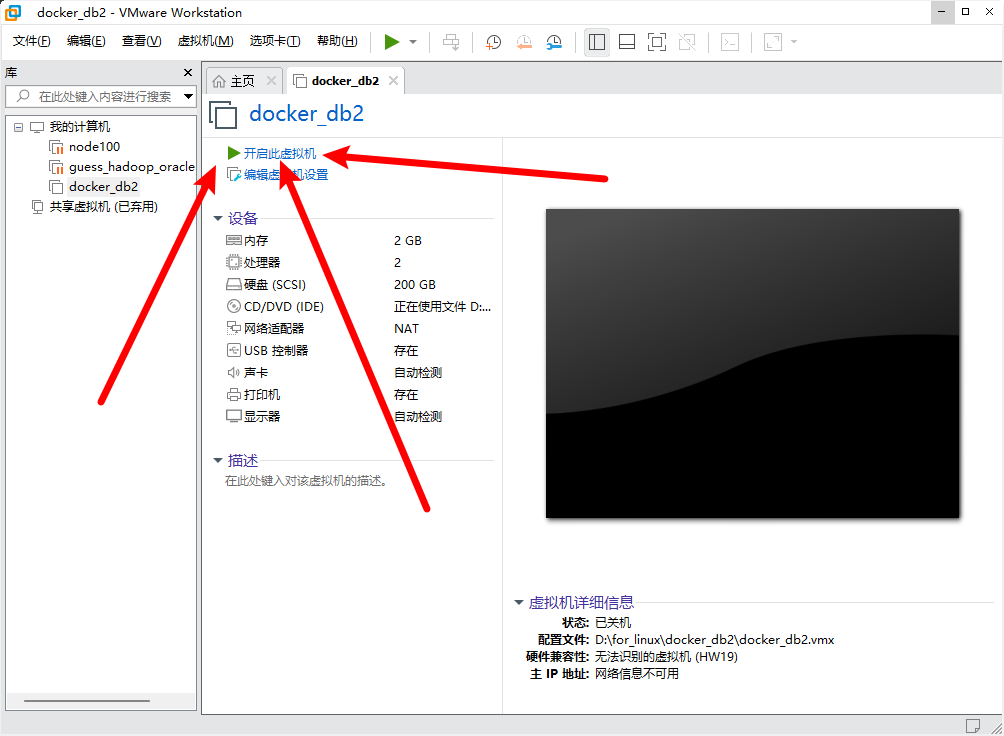
步骤5:在VM虚拟机中登录Linux系统并查看IP地址(记住自己的IP地址后续使用)
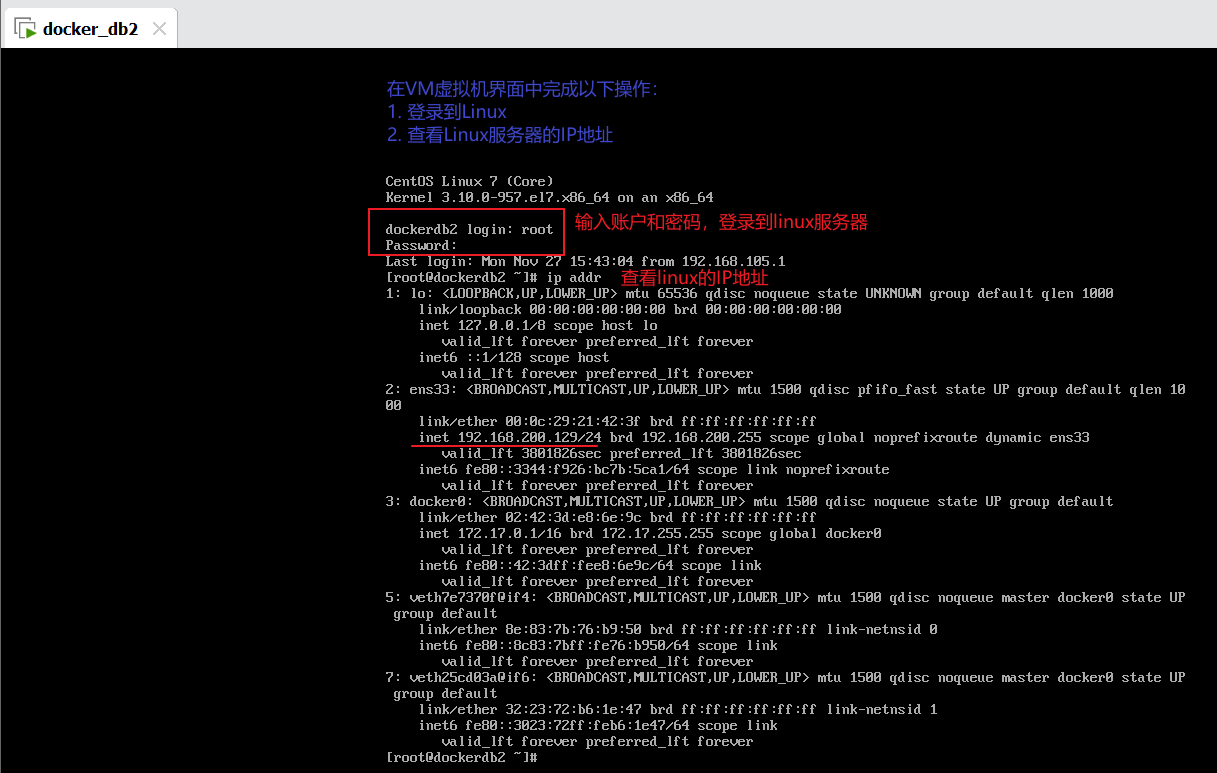
3. 远程连接GaussDB
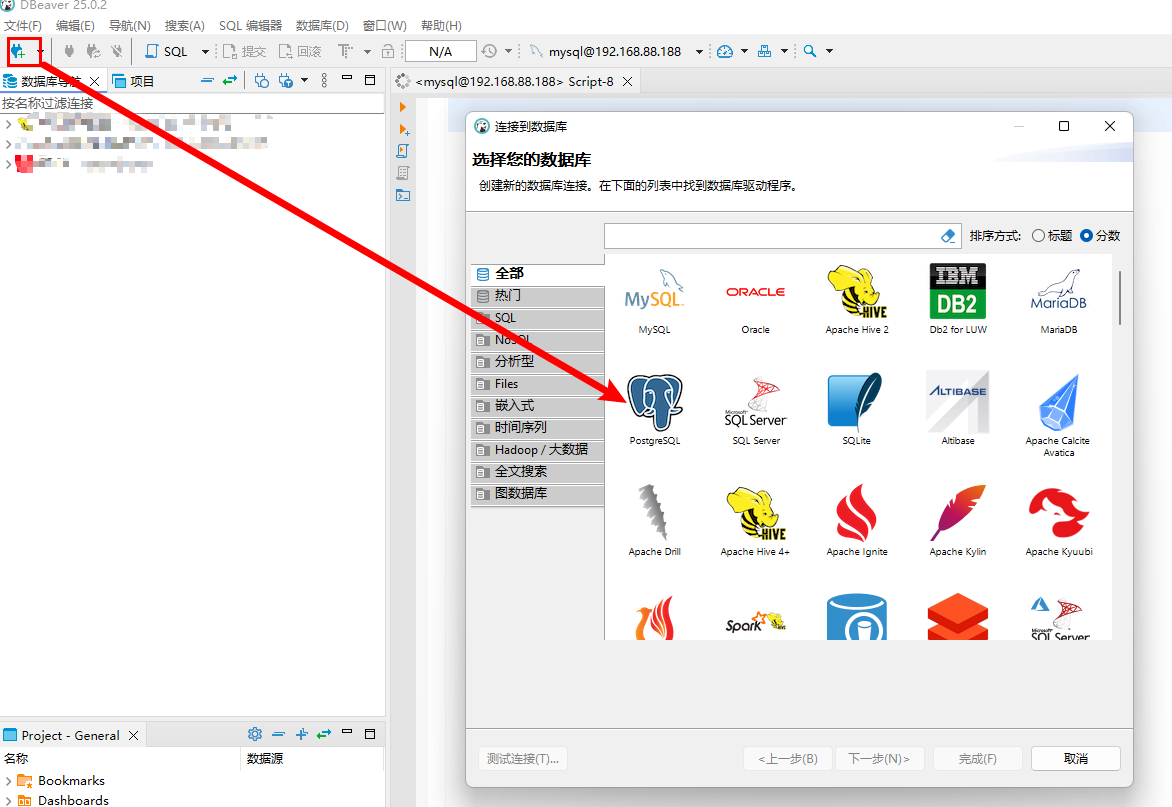
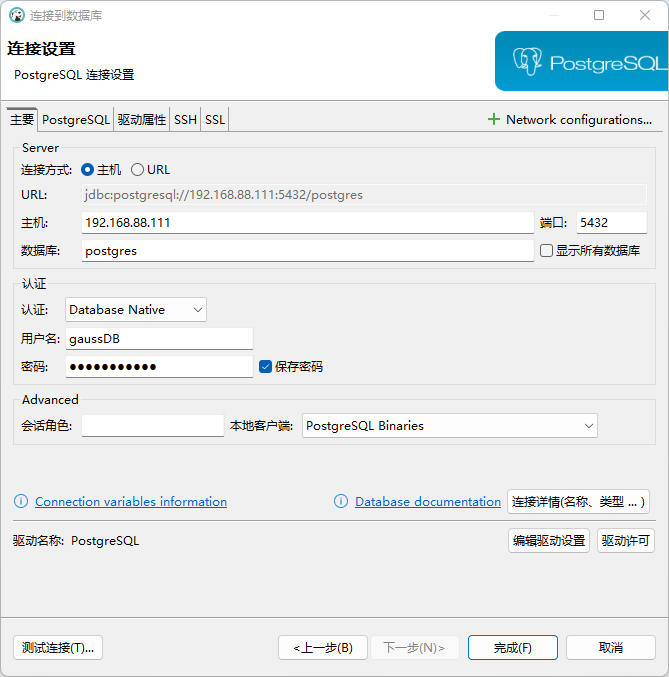
使用DBeaver客户端工具连接GaussDB数据库:
步骤1:新建连接,数据源选择PostgreSQL(GaussDB 是基于PostgreSQL开发的)
步骤2:输入服务器IP地址 、端口号、数据库名称、用户名、密码
1
2
3
4
5
IP地址 : 前面查看到的Linux系统IP地址
端口号 : 5432
数据库 : postgres
用户名 : gaussdb
密码 : Gaussdb@123
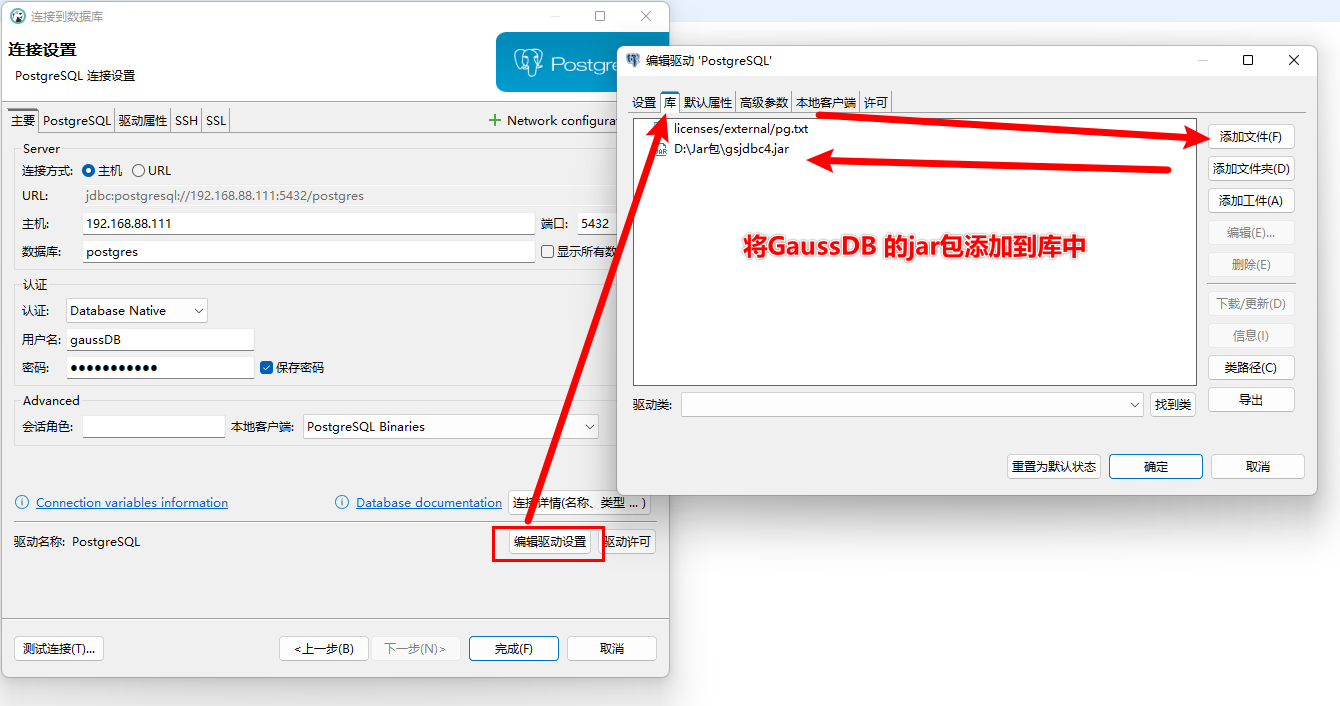
步骤3:下载或添加相关驱动包
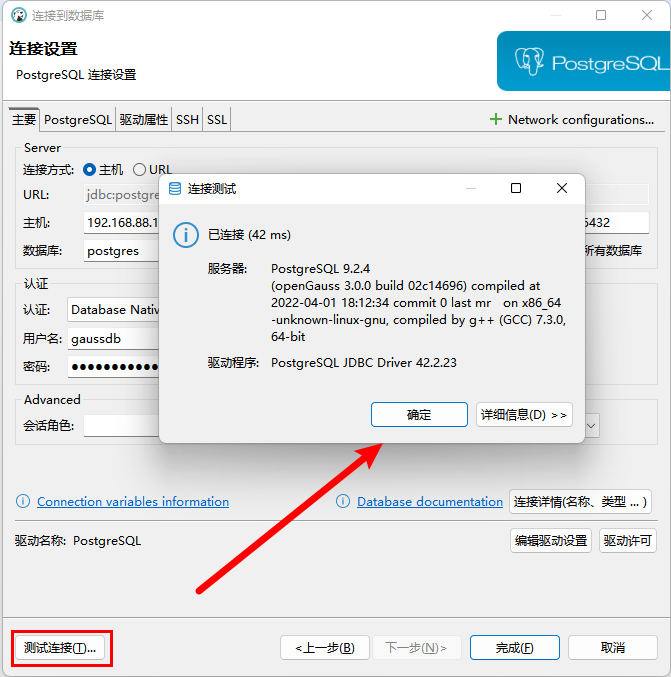
步骤4:测试连接
4. GaussDB的基本使用
4.1 创建数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
1.创建数据库
create database 数据库名
[owner 数据库所有者] -- 可以省略不写,如果不写为当前用户
[template 模板名称] -- 系统默认有三个模板,template0、template1、gaussdb
[encoding 字符编码] -- utf8、gbk
[DBCOMPATIBILITY 指定兼容的数据库类型] -- A(oracle,默认),B(mysql),C(teradata)
*/
-- 创建一个数据库,所有者为当前用户,字符编码是 utf8,兼容oracle数据库
create database db_test
encoding 'utf8'
DBCOMPATIBILITY 'A';
-- 删除数据库
drop database db_test;
4.2 创建表空间
在 GaussDB 中,表空间是数据库物理存储的逻辑分组,用于管理数据文件的存储位置和组织方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
-- 创建普通表空间(指定物理存储路径,支持多个数据文件)
CREATE TABLESPACE ts_data1
RELATIVE LOCATION 'tablespace/ts_data1' -- 相对于GaussDB数据目录的路径
MAXSIZE 1G; -- 最大存储空间1G
-- 若需指定绝对路径(需确保路径存在且数据库用户有读写权限):
CREATE TABLESPACE ts_data2
LOCATION '/data/gaussdb/tablespace/ts_data2';
-- 创建表时指定表空间
CREATE TABLE employees (
id INT,
name VARCHAR(50)
) TABLESPACE ts_data1; -- 指定表空间
-- 创建索引时指定表空间(提升索引访问性能)
CREATE INDEX idx_employees_name
ON employees(name)
TABLESPACE ts_index; -- 单独的索引表空间
-- 先删除表空间内的所有对象(表、索引等),或使用CASCADE级联删除
DROP TABLESPACE ts_data
CASCADE; -- 强制删除(包含其中的所有对象)
-- 查看当前系统中有哪些数据库
select * from pg_database;
-- 查看当前数据库中有哪些表空间
select * from pg_tablespace;
4.3 创建数据表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-- 创建表
create table if not EXISTS test
(
id INT,
name VARCHAR2(20)
);
-- if not EXISTS 如果系统中不存在这个表才创建,否则不创建,防止出现语法报错
-- 删除表
drop table if exists test;
-- if exists 如果系统中存在这张表才删除,否则不删除
-- 创建的表默认是行式存储
create table if not EXISTS test1
(
id INT,
name VARCHAR2(20)
)WITH(orientation=row);
-- 创建列式存储的表
create table if not EXISTS test2
(
id INT,
name VARCHAR2(20)
)WITH(orientation=column);
4.4 数据类型
GaussDB中的数据类型分类:
- 数值类型
- 字符类型
- 布尔类型
- 日期类型
- 数组类型

数组类型示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
create table if not exists test1(
id integer,
name text,
brother text[], -- 数组类型
Relatives text[][]
);
<!-- insert into test1 values(1,'张三','{"张一","张二"}','{{"老张","张爷爷"},{"小赵","赵姨娘"}}'); -->
select * from test1;
-- 1 张三 {张一,张二} {{老张,张爷爷},{小赵,赵姨娘}}
select * from test1 where brother[1] like '张%';
4.5 DQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
CREATE TABLE sales (
item VARCHAR(10),
year VARCHAR(4),
quantity INT
);
INSERT INTO sales VALUES('apple', '2018', 800);
INSERT INTO sales VALUES('apple', '2018', 1000);
INSERT INTO sales VALUES('banana', '2018', 500);
INSERT INTO sales VALUES('banana', '2018', 600);
INSERT INTO sales VALUES('apple', '2019', 1200);
INSERT INTO sales VALUES('banana', '2019', 1800);
-- select into 用于根据查询结果创建一个新表,并且将查询到的数据插入到新表中。
select *
into sales1
from sales
where quantity = 1800;
-- 查看有哪些表
select * from information_schema.tables
where table_schema = 'schema_name';
-- 高斯数据库支持 limit 语法
-- 高斯数据库是由 pg 数据库(postgre) 魔改来的
/*
书写顺序
select --> from --> Join on --> where --> group by --> having --> order by --> limit
执行顺序
from --> join on --> where --> group by -->having --> select --> order by --> limit
limit 作用就是限制查询结果的显示数量
limit 3 表示只显示查询结果的前3行数据
*/
select * from sales
limit 3;
-- limit 2,3 跳过前2行,查询后面3行的数据
-- 也就是显示 3 4 5 行数据
select * from sales
limit 2,3;
/*
3. 分组的区别
高斯数据库支持多维度的分组
*/
-- 我们希望通过多个维度来分析销量情况
-- 比如分别计算 每个产品的销量 和 每个年度的销量 和 每个产品,每个年度的销量,
-- 并且将查询结果上下合并在一起
-- 每个产品的销量
select item,'所有年度' as year,sum(quantity)
from sales
group by item
union all
-- 每个年度的销量
select '所有产品' as item,year ,sum(quantity)
from sales
group by year
union all
-- 每个产品,每个年度
select item,year ,sum(quantity)
from sales
group by item,year;
-- 高斯数据库提供了一种特殊的语法 grouping sets
-- 可以在一条查询语句中同时对多个维度的数据进行统计分析
select nvl(item,'所有产品') as item,
nvl(year,'所有年度') as year,
sum(quantity)
from sales
group by grouping sets ((item,year),item,year);
-- 想当时使用 (item,year), (item) ,(year) 分组
-- 计算 每个产品,每个年度的销量 和 每个产品的销量 和 总销量
-- 每个产品的销量
select item,'所有年度' as year,sum(quantity)
from sales
group by item
union all
-- 每个产品,每个年度
select item,year ,sum(quantity)
from sales
group by item,year
union all
select '所有产品' as item,'所有年度' as year,sum(quantity)
from sales;
-- 使用 rollup 进行分组
select nvl(item,'所有产品') as item,
nvl(year,'所有年度') as year,
sum(quantity)
from sales
group by rollup(item,year);
-- 相当于 根据 (item,year) 和 (item) 和 ()
-- 比如有 rollup (a,b,c) 相当于 (a,b,c) (a,b) (a) 和 ()
5. PLSQL概述
5.1 PLSQL
PL/SQL(Procedure Language/SQL)是一种基于SQL语句的编程语言,它包含两块PL部分内容(判断,循环)和SQL部分内容。当我们遇到复杂需求时,单单用SQL语句很难实现,此时可以使用PL/SQL语言来完成。用更加简单的方式实现这个需求。
PL/SQL :在普通SQL基础上,增加了变量、循环、判断等编程功能,能写更复杂的逻辑。
PLSQL的好处:
- 复用性强:写好一个存储过程,多处调用,避免重复代码。
- 减少网络开销:逻辑在数据库内部执行,避免程序与数据库频繁交互。
- 数据更安全:敏感操作封装在数据库内,避免暴露给外部程序。
小结:
PL/SQL 是专为数据库操作设计的编程语言,能直接在数据库中写”小程序”(如:存储过程、函数),让复杂的数据处理更高效、更省事。
5.2 PLSQL的基本结构
一个PLSQL程序一般由三个部分组成:
1
2
3
4
5
6
7
8
9
10
11
[declare
-- 声明变量
]
begin -- 开始执行plsql代码
-- plsql代码
[exception -- 捕获异常
-- 异常处理
]
end; -- 结束执行plsql代码
注意:
- 对于新手来说,在写完begin后立刻写 end; end后面注意加上分号
- 每写完一条plsql代码,结尾一定要加上分号,否则报错
Oracle的语法方式:
1
2
3
4
BEGIN
-- 将字符串输出到消息栏
RAISE info 'hello world';
END;
Postgre的语法方式:
1
2
3
4
5
DO $$
BEGIN
-- 将字符串输出到消息栏
RAISE NOTICE 'hello world';
END $$;
6. 数据准备
客户表:customer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 客户表
CREATE TABLE customer (
customer_id VARCHAR(20) PRIMARY KEY, -- 客户ID(如身份证号)
customer_name VARCHAR(50) NOT NULL, -- 客户姓名
mobile VARCHAR(15), -- 手机号
id_card VARCHAR(20) unique NOT NULL, -- 身份证号(唯一约束)
address VARCHAR(200), -- 联系地址
credit_score INT CHECK (credit_score BETWEEN 0 AND 100), -- 信用评分
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 创建时间
);
INSERT INTO customer (customer_id, customer_name, mobile, id_card, address, credit_score)
VALUES
('330102200001011234', '张三', '13800001111', '330102200001011234', '杭州市西湖区', 85),
('330103199002022345', '李四', '13900002222', '330103199002022345', '上海市浦东新区', 45),
('330104198503033456', '王五', '13700003333', '330104198503033456', '北京市海淀区', 92),
('330105197712044567', '赵六', '13600004444', '330105197712044567', '广州市天河区', 30);

产品表:loan_product
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 产品表
CREATE TABLE loan_product (
product_id INT PRIMARY KEY, -- 产品ID
product_name VARCHAR(50) NOT NULL, -- 产品名称(如“个人消费贷”)
min_amount NUMERIC(15,2), -- 最低贷款金额
max_amount NUMERIC(15,2), -- 最高贷款金额
interest_type VARCHAR(20) CHECK (interest_type IN ('固定利率', '浮动利率')), -- 利率类型
base_rate NUMERIC(5,2), -- 基准利率(如5.00表示5%)
term_range VARCHAR(50), -- 贷款期限范围(如“12-60个月”)
description TEXT -- 产品描述
);
INSERT INTO loan_product (product_id, product_name, min_amount, max_amount, interest_type, base_rate, term_range)
VALUES
(1, '个人消费贷', 10000.00, 500000.00, '固定利率', 4.35, '12-60个月'),
(2, '企业经营贷', 500000.00, 5000000.00, '浮动利率', 5.50, '24-120个月'),
(3, '车贷', 50000.00, 300000.00, '固定利率', 6.00, '12-36个月');

申请表:loan_application
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
CREATE TABLE loan_application (
application_id SERIAL PRIMARY KEY, -- 申请编号(自增)
customer_id VARCHAR(20) REFERENCES customer(customer_id), -- 客户ID
product_id INT REFERENCES loan_product(product_id), -- 产品ID
apply_amount NUMERIC(15,2) NOT NULL, -- 申请金额
apply_term INT NOT NULL, -- 申请期限(月)
apply_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 申请时间
status VARCHAR(20) CHECK (status IN ('待审核', '已通过', '已拒绝')), -- 申请状态
remark TEXT -- 审核备注
);
-- 张三申请个人消费贷(已通过)
INSERT INTO loan_application (customer_id, product_id, apply_amount, apply_term, status, remark)
VALUES ('330102200001011234', 1, 200000.00, 24, '已通过', '客户信用评分高,收入稳定');
-- 李四申请企业经营贷(已拒绝)
INSERT INTO loan_application (customer_id, product_id, apply_amount, apply_term, status, remark)
VALUES ('330103199002022345', 2, 1000000.00, 36, '已拒绝', '信用评分不足,无抵押物');
-- 王五申请车贷(待审核)
INSERT INTO loan_application (customer_id, product_id, apply_amount, apply_term, status)
VALUES ('330104198503033456', 3, 150000.00, 24, '待审核');
-- 赵六申请个人消费贷(已通过)
INSERT INTO loan_application (customer_id, product_id, apply_amount, apply_term, status, remark)
VALUES ('330105197712044567', 1, 50000.00, 12, '已通过', '小额贷款,风险可控');

放款表:loan_disbursement
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 放款表
CREATE TABLE loan_disbursement (
loan_id SERIAL PRIMARY KEY, -- 贷款编号(自增)
application_id INT REFERENCES loan_application(application_id), -- 申请编号
disbursed_amount NUMERIC(15,2) NOT NULL, -- 实际放款金额
interest_rate NUMERIC(5,2) NOT NULL, -- 实际执行利率
start_date DATE NOT NULL, -- 贷款起始日
end_date DATE NOT NULL, -- 贷款到期日
repayment_method VARCHAR(20) CHECK (repayment_method IN ('等额本息', '等额本金', '一次性还本付息')) -- 还款方式
);
-- 张三的贷款放款(关联申请ID=1)
INSERT INTO loan_disbursement (application_id, disbursed_amount, interest_rate, start_date, end_date, repayment_method)
VALUES (1, 200000.00, 4.35, '2023-01-01', '2025-01-01', '等额本息');
-- 赵六的贷款放款(关联申请ID=4)
INSERT INTO loan_disbursement (application_id, disbursed_amount, interest_rate, start_date, end_date, repayment_method)
VALUES (4, 50000.00, 4.35, '2023-03-15', '2024-03-15', '等额本金');

还款表:repayment_schedule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
-- 还款表
CREATE TABLE repayment_schedule (
schedule_id SERIAL PRIMARY KEY, -- 还款计划ID(自增)
loan_id INT REFERENCES loan_disbursement(loan_id), -- 贷款编号
due_date DATE NOT NULL, -- 应还款日
due_amount NUMERIC(15,2) NOT NULL, -- 应还金额(本金+利息)
paid_amount NUMERIC(15,2) DEFAULT 0, -- 已还金额
paid_date DATE, -- 实际还款日
status VARCHAR(20) CHECK (status IN ('未到期', '已结清', '逾期')) -- 还款状态
);
-- 张三的还款计划(贷款ID=1,24期等额本息)
DO $$
DECLARE
v_due_date DATE := '2023-02-01'; -- 首期还款日
v_monthly_payment NUMERIC := 8774.32; -- 等额本息月供(假设值)
BEGIN
FOR i IN 1..24 LOOP
INSERT INTO repayment_schedule (loan_id, due_date, due_amount, status)
VALUES (1, v_due_date, v_monthly_payment,
CASE WHEN i <= 12 THEN '已结清' ELSE '未到期' END);
v_due_date := v_due_date + INTERVAL '1 month';
END LOOP;
END $$;
-- 赵六的还款计划(贷款ID=2,12期等额本金)
DO $$
DECLARE
v_due_date DATE := '2023-04-15'; -- 首期还款日
v_principal NUMERIC := 4166.67; -- 每月本金(50000/12)
v_interest NUMERIC := 50000 * 0.0435 / 12; -- 首月利息
BEGIN
FOR i IN 1..12 LOOP
INSERT INTO repayment_schedule (loan_id, due_date, due_amount, status)
VALUES (2, v_due_date, v_principal + v_interest,
CASE WHEN i <= 3 THEN '逾期' ELSE '未到期' END);
v_due_date := v_due_date + INTERVAL '1 month';
v_interest := (50000 - (i-1)*v_principal) * 0.0435 / 12; -- 剩余本金计算利息
END LOOP;
END $$;
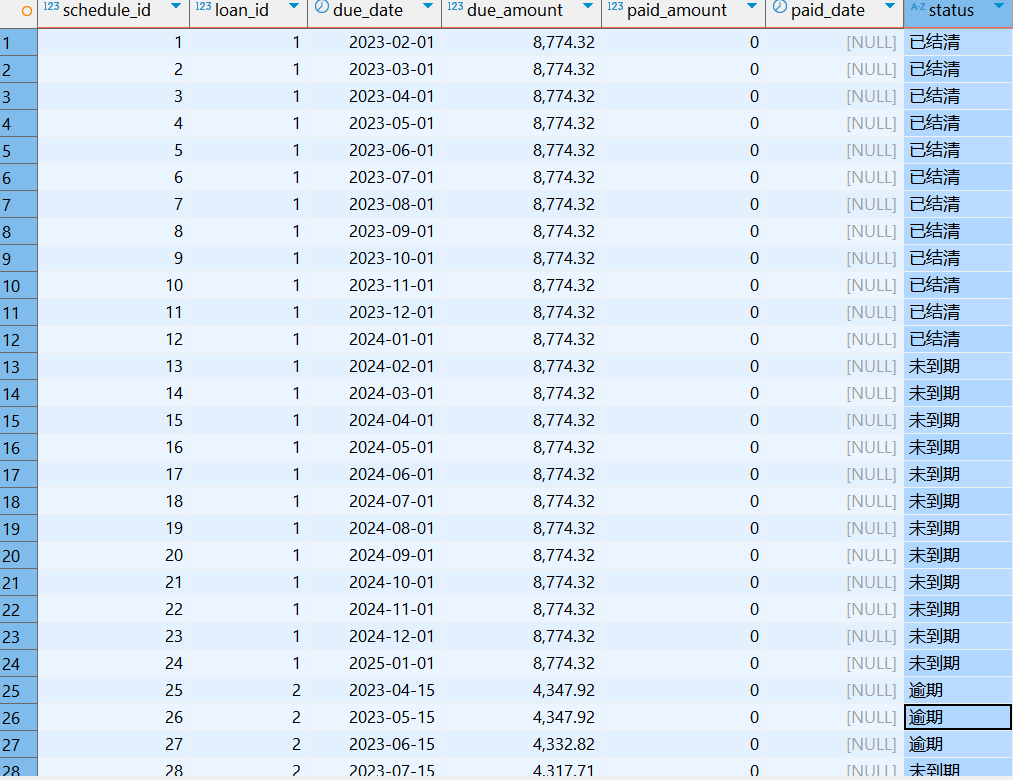
逾期记录表:overdue_record
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 逾期记录表
CREATE TABLE overdue_record (
record_id SERIAL PRIMARY KEY, -- 逾期记录ID
loan_id INT REFERENCES loan_disbursement(loan_id), -- 贷款编号
overdue_days INT NOT NULL, -- 逾期天数
overdue_amount NUMERIC(15,2) NOT NULL, -- 逾期金额(含罚息)
penalty_rate NUMERIC(5,2), -- 罚息利率
resolved BOOLEAN DEFAULT FALSE -- 是否已处理
);
-- 赵六的逾期记录(贷款ID=2,前3期逾期)
INSERT INTO overdue_record (loan_id, overdue_days, overdue_amount, penalty_rate, resolved)
VALUES
(2, 15, 4500.00, 0.05, FALSE), -- 第1期逾期
(2, 30, 4300.00, 0.05, FALSE), -- 第2期逾期
(2, 45, 4100.00, 0.05, TRUE); -- 第3期逾期(已处理)

7. 变量
7.1 什么是变量
-
变量就是用来暂时存储数据的,其中存储的数据可以多次改变。
-
常量是用来暂时存储数据的,其中存储的数据不能进行改变。
- 需在声明时初始化。(关键字 CONSTANT)
7.2 语法
1
2
3
4
5
6
7
declare
变量名 数据类型; -- 声明变量(未初始化) 默认为null
变量名 数据类型 := 初始值; -- 声明变量并初始化值
常量名 CONSTANT 数据类型 := 初始值; -- 声明常量并初始化值
begin
-- plsql代码
end;
变量名要求:
-
只能是字母,数字,下划线,$,#
-
变量名的首字符必须是字母,一般使用
v_或var_作为变量名开头 -
不允许使用关键字
-
变量名可能由多个单词组成,单词之间用 _ 拼接
示例:
1
2
3
4
5
6
7
declare
var_name varchar2(20) := 'SMITH'; -- 声明变量并初始化值
var_age number; -- 只声明变量,不赋值,默认为NULL
var_sex CONSTANT varchar2(5) := '男'; -- 声明常量
begin
-- PLSQL代码
end;
7.3 变量的赋值
赋值就是将数据传入变量中,由变量临时存储起来,方便后续的使用。
7.3.1 使用 := 进行赋值
为了防止产生歧义,在PLSQL中使用 := 表示赋值, = 表示等值比较。
语法: 适合知道变量需要存入的具体值
1
2
3
4
5
6
declare
变量名1 数据类型; -- 先声明变量后再进行赋值
变量名2 数据类型 := 初始值; -- 在声明变量时直接初始化值
begin
变量名1 := 数据值; -- 给变量赋值
end;
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/*
为了防止产生歧义,在PLSQL中使用 := 表示赋值, = 表示等值比较
方式一:使用 := 进行赋值
declare
-- 1.可以在声明变量的时候顺便赋值
变量名1 数据类型 := 值1;
-- 2.声明变量时也可以先不赋值
变量名2 数据类型;
begin
-- 3.在begin 和 end; 之间去修改变量的值
变量名1 := 值2;
变量名2 := 值3;
end;
适合知道变量需要存入的具体的值
*/
DECLARE
v_num INT := 10;
v_str VARCHAR2(20); -- 如果变量在声明的时候没有赋值,那么它的初始值是 null 值
-- 声明常量 CONSTANT
v_num1 CONSTANT INT := 200;
BEGIN
-- 在PLSQL中,代码是从上往下依次执行的,在不同的位置,变量的值可以不同
-- 输出语句
RAISE NOTICE 'v_num: %',v_num; -- 10
RAISE NOTICE 'v_str: %',v_str; -- null
-- 变量只有在声明的时候需要写数据类型,在begin 和end之间使用时不需要添加数据类型
v_num := 100;
v_str := '张三';
RAISE NOTICE 'v_num: %',v_num; -- 100
RAISE NOTICE 'v_str: %',v_str; -- 张三
--v_num1 := 300; -- 常量只能在声明的时候赋值,在后续不能修改常量的值
RAISE NOTICE 'v_num1: %',v_num1;
END;
7.3.2 使用SELECT INTO进行赋值
当变量的值需要通过查询语句,对表中数据查询得到时,一般使用 SELECT INTO进行赋值。
语法: 适用于查询获取到的动态值
1
2
3
4
5
6
7
8
9
declare
变量名1 数据类型;
变量名2 数据类型;
begin
SELECT 字段1,字段2
INTO 变量名1,变量名2
FROM 表名
WHERE 条件; -- 注意:根据条件查询获取到的值只能是一行两列
end;
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/*
当变量的值需要通过查询语句,对表中数据查询得到时,一般使用 select into 进行赋值
语法
DECLARE
-- 声明两个变量
变量名1 数据类型;
变量名2 数据类型;
BEGIN
SELECT 字段1,
字段2
INTO 变量名1,
变量名2
FROM 表名
WHERE 条件;
END;
注意事项:
1.select 后字段的值赋值给 into 后面对应位置的变量,
要求字段的数量和变量的数量相同,对应位置的变量和字段数据类型相同
2.select into 也称为单行查询数据,要求查询结果有且只能有一条数据
*/
-- 查询客户表中编号是330102200001011234的客户姓名和手机号,用变量接收查询结果,并把值打印出来
DECLARE
v_customer_name VARCHAR2(50);
v_mobile VARCHAR2(15);
BEGIN
SELECT customer_name,
mobile
INTO v_customer_name,
v_mobile
FROM customer
WHERE customer_id = '330102200001011234';
-- 输出多个字段的内容,需要使用两个% ,并且之间需要使用逗号分隔
RAISE NOTICE '客户名字: % , 手机号: %',v_customer_name,v_mobile;
END;
7.3 变量数据类型
7.3.1 基本数据类型
基本数据类型包含:
-
字符类型:
char、varchar、varchar2、text - 数字类型
- 整数:
tinyint、smallint、int、bigint - 小数:
float、double - 带精度小数:
number、decimal
- 整数:
-
日期类型:
date、timestamp - 其它类型:
boolean、array
示例:
1
2
3
4
5
6
7
8
9
10
11
DECLARE
v_customer_name TEXT;
v_address TEXT;
BEGIN
SELECT customer_name,address
INTO v_customer_name,v_address
FROM customer
WHERE customer_id = '330102200001011234';
RAISE NOTICE '姓名: % , 地址: %', v_customer_name,v_address;
END;
7.3.2 复杂数据类型
GaussDB和ORACLE一样提供了一种特有的类型称为属性类型。可以在不清楚类型的情况下,来定义变量。ORACLE中的属性类型:%TYPE(引用列的类型)、%ROWTYPE(行记录的类型)
属性类型的优点:
- 不需要知道被引用的列的具体类型
- 随着被引用对象的数据类型变化而之改变(如果更改了被引用对象的数据类型,那么PL/SQL在运行时变量的数据类型也会随之改变)
7.3.2.1 %TYPE类型
作用:引用某表某列的字段类型
语法:
1
2
declare
变量名 表名.字段名%type; -- 表示变量的数据类型和表中字段的数据类型相同
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/*
declare
变量名 表名.字段名%type;
表示变量的数据类型和 表中字段的数据类型相同
*/
-- 查询客户表中编号是330102200001011234的客户姓名和手机号,用变量接收查询结果,并把值打印出来
DECLARE
-- 变量的数据类型和customer表中customer_name字段的数据类型相同
v_customer_name customer.customer_name%type;
v_mobile customer.mobile %type;
BEGIN
SELECT customer_name,mobile
INTO v_customer_name,v_mobile
FROM customer
WHERE customer_id = '330102200001011234';
RAISE INFO '客户名字: % , 手机号: %',v_customer_name,v_mobile;
END;
7.3.2.2 %ROWTYPE类型
作用: 标识某个表的行记录类型
语法:
1
2
declare
变量名 表名%rowtype; -- %rowtype类型的变量可以存储表中一整行的数据(包含了表中的所有字段)
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/*
declare
变量名 表名%rowtype;
%rowtype类型的变量可以存储表中一整行的数据,包含了表中的所有字段
*/
-- 查询客户表中编号是330102200001011234的客户信息,用变量接收查询结果,并把值打印出来
DECLARE
-- 变量的数据类型包括customer表一整行字段
v_customer customer%rowtype;
BEGIN
SELECT *
INTO v_customer
FROM customer
WHERE customer_id = '330102200001011234';
RAISE INFO '客户名字: % , 地址: %',v_customer.customer_name,v_customer.address;
END;
7.3.2.3 RECORD记录类型
如果我们的查询语句查询结果包含多个字段,且字段来源于不同的表,此时无法使用 %rowtype 类型,我们可以自己去定义一个数据类型(自定义数据类型),包含上面的所有字段,然后声明变量去使用这个数据类型。
使用方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
declare
-- 1.定义一个记录类型(自定义数据类型)
type 记录名 is record(
变量名1 数据类型,
变量名2 数据类型,
.....
);
-- 2.声明一个记录类型的变量
变量名 记录名;
begin
-- 3.在访问记录类型里面的变量的时候需要使用记录类型定义的变量来访问
记录类型变量.变量名
end;
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
/*
record:记录类型
如果我们的查询语句查询结果包含多个字段,且字段来源于不同的表,此时无法使用 %rowtype 类型,我们可以自己去定义一个数据类型,包含上面的所有字段,然后声明变量去使用这个数据类型
使用步骤:
declare
-- 1.定义一个记录类型(自定义数据类型)
type 记录名 is record(
变量名 数据类型,
变量名 数据类型,
.....
);
-- 2.声明一个记录类型的变量
变量名 记录名;
begin
-- 3.在访问记录类型里面的变量的时候需要使用记录类型定义的变量来访问
记录类型变量.变量名
end;
*/
-- 编写一个PLSQL代码,使用记录类型
DECLARE
-- 1.声明记录类型能够存储下面的字段
TYPE info_record IS RECORD(
customer_id customer.customer_id%TYPE
,customer_name customer.customer_name%TYPE
,mobile customer.mobile%TYPE
,application_id loan_application.application_id%TYPE
,apply_amount loan_application.apply_amount%TYPE
,apply_time loan_application.apply_time%TYPE
,status loan_application.status%TYPE
);
-- 2.声明变量使用记录类型
v_info_record info_record;
BEGIN
SELECT c.customer_id,
c.customer_name,
c.mobile,
la.application_id,
la.apply_amount,
la.apply_time,
la.status
INTO v_info_record
FROM customer c
JOIN loan_application la ON c.customer_id = la.customer_id
WHERE c.customer_name = '张三';
RAISE NOTICE '客户编号: %',v_info_record.customer_id;
RAISE NOTICE '客户名字: %',v_info_record.customer_name;
RAISE NOTICE '客户手机号: %',v_info_record.mobile;
RAISE NOTICE '贷款申请编号: %',v_info_record.application_id;
RAISE NOTICE '贷款申请金额: %',v_info_record.apply_amount;
RAISE NOTICE '贷款申请时间: %',v_info_record.apply_time;
RAISE NOTICE '贷款申请状态: %',v_info_record.status;
END;
7.4 课堂练习
数据准备:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
-- 数据准备
CREATE TABLE emp(
empno INT, -- 员工编号
ename VARCHAR(22), -- 员工姓名
job VARCHAR(22), -- 工作岗位
mgr INT, -- 上级领导编号
hiredate DATE, -- 入职日期
sal DECIMAL(11,2), -- 员工工资
comm DECIMAL(11,2), -- 佣金
deptno INT -- 对应部门编号
);
/*添加数据*/
INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,to_date('19-4-1987','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,to_date('23-5-1987','dd-mm-yyyy'),1100,NULL,20);
INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);
/*创建表 dept*/
create table dept (
deptno INT,
dname varchar(22),
loc varchar(22)
);
/*添加数据*/
INSERT INTO dept(deptno, dname, loc) VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept(deptno, dname, loc) VALUES (20, 'RESEARCE', 'DAKKAS');
INSERT INTO dept(deptno, dname, loc) VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO dept(deptno, dname, loc) VALUES (40, 'OPERATIONS', 'BOSTON');
create table salgrade(
grade INT,
losal DECIMAL(11,2),
hisal DECIMAL(11,2)
);
/*添加数据*/
INSERT INTO salgrade(grade, losal, hisal) VALUES (1, 700, 1200);
INSERT INTO salgrade(grade, losal, hisal) VALUES (2, 1201, 1400);
INSERT INTO salgrade(grade, losal, hisal) VALUES (3, 1401, 2000);
INSERT INTO salgrade(grade, losal, hisal) VALUES (4, 2001, 3000);
INSERT INTO salgrade(grade, losal, hisal) VALUES (5, 3001, 9999);
需求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/*
使用plsql代码实现查询员工编号为 7934 的员工所在部门工资最高的员工姓名和工资,并输出该员工的姓名和工资
提醒:1.可以使用一个SQL语句单独完成所有的查询,在最外层使用into进行变量赋值
2.也可以拆分成多个简单查询语句,中间使用变量传递数据,实现查询结果
*/
-- 方式一:一次性写完整个SQL语句
DECLARE
v_ename VARCHAR(20);
v_sal INT;
BEGIN
SELECT ename,
sal
INTO v_ename,
v_sal
FROM emp
WHERE (deptno,sal) = (SELECT deptno,
MAX(sal)
FROM emp
WHERE deptno = (SELECT deptno
FROM emp
WHERE empno = 7934)
GROUP BY deptno);
RAISE NOTICE 'v_ename: %,v_sal: %',v_ename,v_sal;
END;
-- 方式二:将一个复杂的SQL语句拆分成多个简单的SQL语句
DECLARE
v_deptno INT;
v_max_sal INT;
v_ename VARCHAR(20);
BEGIN
-- 1.先查询 7934 员工的部门
SELECT deptno
INTO v_deptno
FROM emp
WHERE empno = 7934;
-- 2.查询该部门最高工资
SELECT MAX(sal)
INTO v_max_sal
FROM emp
WHERE deptno = v_deptno;
-- 3.查询最高工资员工的姓名
SELECT ename
INTO v_ename
FROM emp
WHERE deptno = v_deptno
AND sal = v_max_sal;
RAISE NOTICE 'v_ename: %,v_sal: %',v_ename,v_max_sal;
END;
在openGauss中, RAISE INFO 和 RAISE NOTICE 的主要区别在于错误级别和日志记录方式:
错误级别差异
- RAISE INFO:属于日志级别信息,通常用于记录非错误性提示或业务逻辑信息,不会中断当前事务。
- RAISE NOTICE:属于通知级别信息,用于报告业务逻辑状态或操作结果,但不会写入客户端日志。
日志记录差异
- RAISE INFO:默认写入服务器日志,但可通过配置参数
log_min_messages控制是否输出到客户端。 - RAISE NOITICE:仅在客户端显示,不会写入服务器日志。
两者均支持格式化字符串和附加信息 (如错误码、提示文本),但NOTICE更侧重于业务层面的即时反馈。
8. 流程控制语句
8.1 分支语句
分支语句:对执行程序中的代码进行判断,有选择的执行某行或某段代码。
8.1.1 IF语句
语法1:单支语句
- 判断一次,一个执行结果
1
2
3
if 条件表达式 then
条件为 true 的时候才会执行的代码;
end if;
示例:
1
2
3
4
5
6
7
8
declare
v_num number := 10;
begin
-- 判断数值是否为偶数
if mod(v_num,2) = 0 then
raise info '% 是偶数',v_num;
end if;
end;
语法2:双支语句
- 判断一次,有两不同的执行结果。
1
2
3
4
5
if 条件表达式 then
条件为 true 的时候才会执行的代码;
else
条件为 false 的时候才会执行的代码;
end if;
示例:
1
2
3
4
5
6
7
8
9
10
declare
v_num number := 11;
begin
-- 判断数值是否为偶数
if mod(v_num,2) = 0 then
raise info '% 是偶数',v_num;
else
raise info '% 是奇数',v_num;
end if;
end;
语法3:多支语句
1
2
3
4
5
6
7
8
9
10
11
12
if 条件表达式1 then
条件表达式1 为 true 的时候才会执行的代码;
elsif 条件表达式2 then
条件表达式2 为 true 的时候才会执行的代码;
elsif 条件表达式3 then
条件表达式3 为 true 的时候才会执行的代码;
.........
elsif 条件表达式N then
条件表达式N 为 true 的时候才会执行的代码;
else
以上所有的条件都为 false 的时候才会执行的代码;
end if;
示例:实现贷款金额分级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
DECLARE
v_loan_amount NUMBER(10,2) := 300000.00;
v_loan_level VARCHAR(20);
BEGIN
IF v_loan_amount < 100000 THEN
v_loan_level := '小额贷款';
ELSIF v_loan_amount < 500000 THEN
v_loan_level := '中等贷款';
ELSE
v_loan_level := '大额贷款';
END IF;
RAISE INFO '贷款等级:%', v_loan_level;
END;
8.1.2 IF语句案例
案例:工资交税
- 大于等于3000部分交1%, 大于等于1500部分交 0.5%,低于1500的不要交税
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
--完成查看指定员工需要交的税的情况,大于等于3000部分交1%, 大于等于1500部分交 0.5%,低于1500的不要交税
DECLARE
v_sal emp.sal%TYPE;
v_tax emp.sal%TYPE;
BEGIN
SELECT sal
INTO v_sal
FROM emp
WHERE empno = 7788;
RAISE NOTICE '工资: %',v_sal;
IF v_sal >= 3000 THEN
v_tax := v_sal * 0.01;
ELSIF v_sal >= 1500 THEN
v_tax := v_sal * 0.005;
ELSE
v_tax := 0;
END IF;
RAISE NOTICE '纳税金额: %',v_tax;
END;
8.1.3 CASE语句
语法1:基于单一表达式的值匹配
1
2
3
4
5
6
CASE expression
WHEN value1 THEN statement1;
WHEN value2 THEN statement2;
……
ELSE statementN;
END CASE;
示例:
1
2
3
4
5
6
7
8
9
10
11
DECLARE
v_loan_status VARCHAR(20) := '逾期';
v_risk_description VARCHAR(50);
BEGIN
CASE v_loan_status
WHEN '逾期' THEN v_risk_description := '发送催收通知';
WHEN '正常' THEN v_risk_description := '定期跟踪';
ELSE v_risk_description := '人工核查';
END CASE;
RAISE INFO '处理建议:%', v_risk_description;
END;
语法2:支持多条件判断
1
2
3
4
5
6
CASE
WHEN condition1 THEN statement1;
WHEN condition2 THEN statement2;
……
ELSE statementN;
END CASE;
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
DECLARE
v_loan_amount NUMBER := 300000.00;
v_loan_level VARCHAR(20);
BEGIN
CASE
WHEN v_loan_amount < 100000 THEN
v_loan_level := '小额贷款';
WHEN v_loan_amount < 500000 THEN
v_loan_level := '中等贷款';
ELSE
v_loan_level := '大额贷款';
END CASE;
RAISE INFO '贷款等级:%', v_loan_level;
END;
8.1.4 CASE语句案例
案例:根据员工薪资确定属于哪类收入人群
- 低于1500 –> 低收入 、 大于1500低于3000 –> 中等收入 、 其他 -> 高收入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
DECLARE
v_sal NUMBER;
BEGIN
-- 查询7788员工的工资
SELECT sal
INTO v_sal
FROM emp
WHERE empno = 7788;
CASE
WHEN v_sal < 1500 THEN
RAISE NOTICE '低收入';
WHEN v_sal < 3000 THEN
RAISE NOTICE '中等收入';
ELSE -- 如果以上条件都为假,输出 高收入
RAISE NOTICE '高收入';
END CASE;
END;
8.1.5 练习题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
-- 随便输入一个年份,判断是否是闰年;使用 mod()函数
do $$
declare
v_year numeric := 2000;
begin
if mod(v_year,4)=0 and mod(v_year,100) != 0 or mod(v_year,400)=0 then
raise notice '% 是闰年',v_year;
else
raise notice '% 是平年',v_year;
end if;
end$$;
/*
请用户输入一个星期,然后输出应该吃的菜名
星期一,酸辣土豆丝
星期二,水煮肉片
星期三,麻婆豆腐
星期四,辣子鸡丁
星期五,小炒肉
周末,喝汤
*/
do $$
declare
v_week varchar(10) := '星期三';
v_cai varchar2(100);
begin
case v_week
when '星期一' then v_cai := '酸辣土豆丝';
when '星期二' then v_cai := '水煮肉片';
when '星期三' then v_cai := '麻婆豆腐';
when '星期四' then v_cai := '辣子鸡丁';
when '星期五' then v_cai := '小炒肉';
when '周末' then v_cai := '喝汤';
end case ;
raise notice '今天%,那就吃%',v_week,v_cai;
end $$
8.2 循环语句
程序中的某一段代码需要被反复执行多次时,就会使用循环语句进行控制。
通常程序中循环要具备三要素:
- 循环初始值
- 循环条件
- 修改循环条件
循环控制语句:
EXIT:立即退出当前循环。EXIT WHEN:满足条件时退出循环。CONTINUE:跳过当前迭代,进入下一次循环。RETURN:直接停止程序。
8.2.1 LOOP循环
语法:直接进入到循环体中执行相关代码
1
2
3
4
5
6
loop
循环体;
循环条件;
迭代条件;
-- 以上代码不分先后,看自己的代码逻辑实现
end loop;
示例:
1
2
3
4
5
6
7
8
9
declare
v number := 1; -- 初始值
begin
loop
raise info '%',v; -- 循环体
exit when v = 10; -- 循环条件 exit 退出循环(满足条件时退出循环)
v := v + 1; -- 迭代条件
end loop;
end;
8.2.2 LOOP循环案例
案例:计算10的阶乘
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
DECLARE
-- 声明一个变量记录循环次数
i INT := 1;
-- 声明一个变量记录累乘的值
v_sum INT := 1;
BEGIN
LOOP
v_sum := i*v_sum; -- 阶乘计算
EXIT WHEN i=10; -- 循环结束条件
i := i + 1; -- 修改循环条件
END LOOP;
RAISE NOTICE '%',v_sum;
END;
案例:计算1到100之间,能被7整除数的和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
DECLARE
-- 声明一个变量记录循环次数
i INT := 1; -- 循环初始值
-- 声明一个变量记录累加的值
v_sum INT := 0;
BEGIN
LOOP
-- 只需要在满足条件的时候去进行累加,不满足条件时,无需进行任何操作
IF MOD(i, 7) = 0 THEN
v_sum := i + v_sum;
END IF;
EXIT WHEN i = 100; -- 循环条件
i := i + 1; -- 修改循环条件
END LOOP;
RAISE NOTICE '%',v_sum;
END;
8.2.3 WHILE循环
语法: 先进行条件判断,再执行循环体中的代码
1
2
3
4
while 条件表达式 loop
循环体;
迭代条件;
end loop;
示例:
1
2
3
4
5
6
7
8
9
10
11
declare
v_num number:=1; -- 循环初始值
begin
-- while中包含循环条件
while v_num<=10 loop
--循环体
raise info '%',v_num;
v_num:=v_num+1; -- 修改循环变量
end loop;
raise info 'WHILE循环执行结束....'
end;
8.2.4 WHILE循环案例
案例:输出100到999之间的水仙花数
- 水仙花的数就是三位数各个位数上的立方等于它本身。例如:153 =>
1*1*1 + 5*5*5 + 3*3*3=153
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
DECLARE
num int := 100; -- 从100开始
bai int; -- 百位数字
shi int; -- 十位数字
ge int; -- 个位数字
sum_cubes int; -- 各位数字的立方和
BEGIN
RAISE INFO '100到999之间的水仙花数有:';
-- 使用WHILE循环遍历100到999
WHILE num <= 999 loop
-- 分解数字的各位
bai := trunc(num / 100);
shi := trunc(num / 10) % 10;
ge := num % 10;
-- 计算各位数字的立方和
sum_cubes := bai*bai*bai + shi*shi*shi + ge*ge*ge;
-- 判断是否为水仙花数
IF sum_cubes = num THEN
RAISE NOTICE '%', num;
END IF;
-- 增加计数器
num := num + 1;
END LOOP;
END;
8.2.5 FOR循环
语法:先判断循环条件,再执行循环体中的代码
1
2
3
4
-- 下面的reverse是倒序的意思
for 变量 in[reverse] 起始值..终止值 loop
--循环体
end loop;
示例:
1
2
3
4
5
6
begin
-- for循环会自动初始化、自动迭代、自动判断
for v in 1..10 loop
raise info '%',v;
end loop;
end;
示例:for 循环遍历集合(查询的结果集作为一个集合)
1
2
3
4
5
begin
for v in (select * from customer) loop
raise info '%',v.customer_name;
end loop;
end;
8.2.6 FOR循环案例
案例:计算发放的员工总工资
1
2
3
4
5
6
7
8
9
10
declare
-- 定义变量:存储员工薪资的累加和
total_sal emp.sal%type := 0;
begin
for v in (select * from emp) loop
total_sal := total_sal + v.sal;
end loop;
raise info '发放的员工总工资为:%',total_sal;
end;
8.2.7 循环控制语句
示例:CONTINUE
1
2
3
4
5
6
7
8
9
10
begin
for v in 1..10 loop
if v = 8 then
CONTINUE; -- 结束本次循环,执行下一次循环
end if;
raise info '%',v;
end loop;
raise info 'CONTINUE 关键字会直接跳过本次循环,进入下次循环。不会影响循环外面的代码';
end;
示例:RETURN
1
2
3
4
5
6
7
8
9
10
begin
for v in 1..10 loop
if v = 8 then
return; -- 终止当前PLSQL程序的执行
end if;
raise info '%',v;
end loop;
raise info 'RETURN 关键字会直接停止程序,我不会执行';
end;
8.3 流程语句练习
-
声明一个记录类型变量,存储产品表的
product_name和base_rate,并查询产品ID为1的信息,输出产品名称和利率。 -
根据客户ID查询其信用评分,并输出风险等级(<60高风险,60-80中风险,≥80低风险)。
-
输入贷款金额,判断其属于“小额贷款”(<10万)、“中等贷款”(10-50万)或“大额贷款”(≥50万),并查询匹配的贷款产品名称(如“个人消费贷”)。
-
输入产品ID和客户ID,查询该产品的基准利率(
base_rate)和客户的信用评分。若信用评分≥80,利率下调0.5%,否则保持原利率。输出最终利率。 -
输入贷款ID,统计其还款计划中“已结清”、“逾期”、“未到期”的笔数,并输出结果。
-
创建一张用户表
USERS,通过循环向表中添加 100 条数据。字段需求如下:user_id:用户ID,使用递增列代替;user_name:用户名称,可以通过统一前缀MyName拼接用户ID;user_sex:用户性别,根据用户ID来决定性别,奇数男,偶数女;user_age:用户年龄,可以通过random()随机函数来控制用户年龄在 18 - 40 之间;
-
编写一个PL/SQL块:在控制台上输出emp中编号为7788的姓名,工资,入职日期和职位,要求在定义变量的时候使用record类型定义。
-
编写一个PL/SQL块:定义两个变量,然后分别输出这两个数的和,差,商,积;
-
编写一个PL/SQL块:在控制台上使用%type类型的变量输出emp表中7902员工的姓名和职位。
-
打印图形
- 使用循环打印,一次仅打印输出一个
*
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
-- 第一个图形(嵌套循环) ****** ****** ****** ****** ****** for i in 1..5 loop for j in 1..6 loop; end loop; end loop; -- 第二个图形(嵌套循环) * ** *** **** ***** DECLARE v_rows NUMBER := 5; -- 控制三角形的行数(可修改此值调整大小) v_i NUMBER; -- 外层循环计数器 v_line TEXT; -- 存储当前行的内容 BEGIN FOR v_i IN 1..v_rows LOOP v_line := ''; -- 初始化当前行 -- 内层循环构建当前行的星号 FOR v_j IN 1..v_i LOOP v_line := v_line || ' *'; -- 拼接星号 END LOOP; RAISE NOTICE '%', v_line; -- 输出当前行 END LOOP; END; * *** ***** ******* ********* * * * * * * * * * ******* ***** *** *
- 使用循环打印,一次仅打印输出一个
附录1:开启虚拟机失败
问题:若打开后,出现如下错误
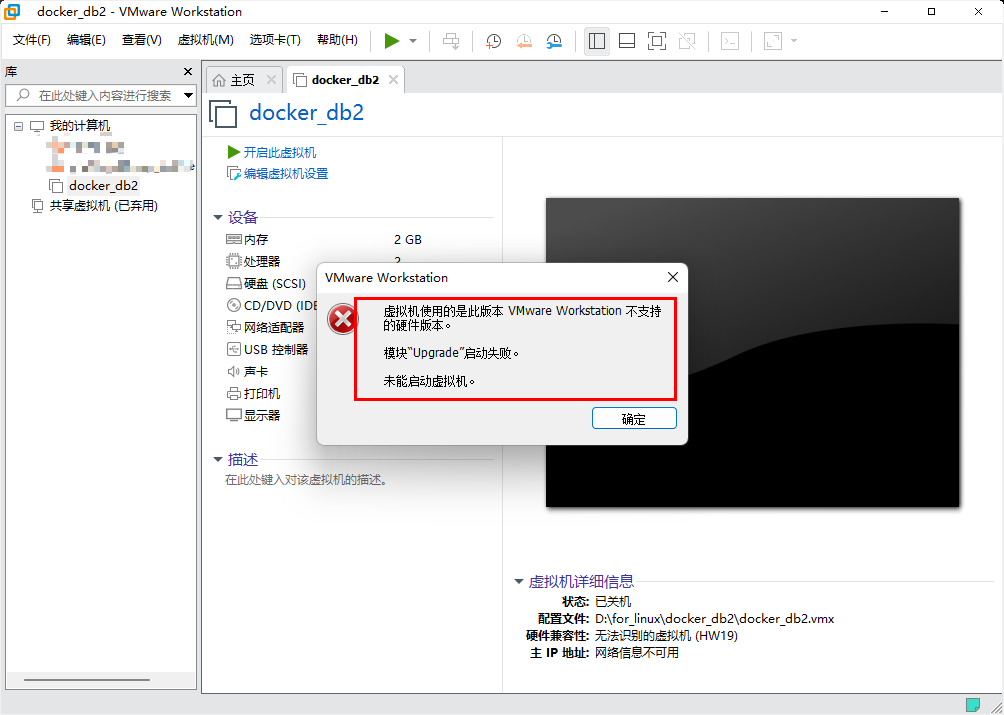
解决方案:找到你自己虚拟机的解压路径,找到 docker_db2.vmx 文件,打开进行编辑
1
2
3
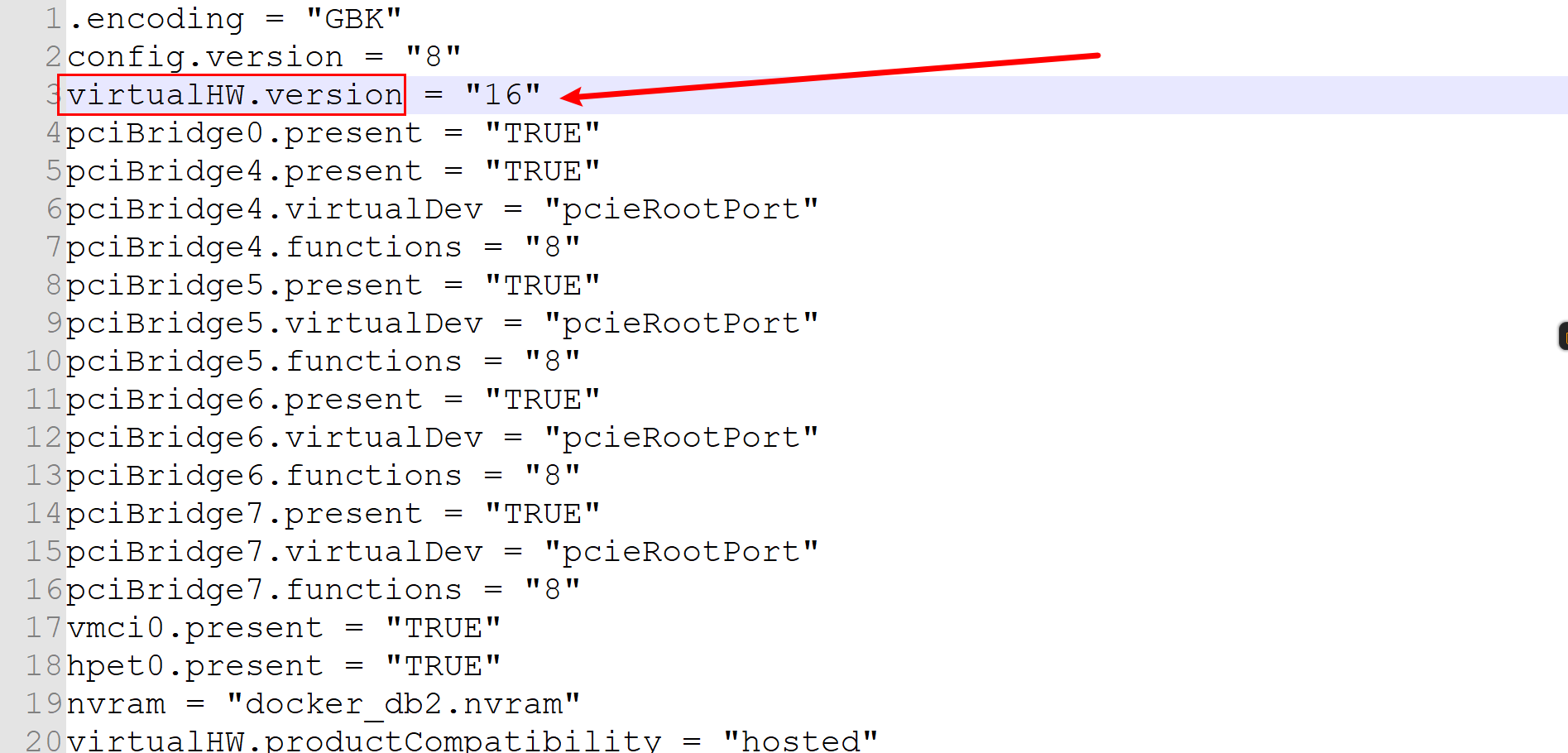
/* 编辑 virtualHW.version 属性值 */
virtualHW.version = "19" == 修改为 ==> virtualHW.version = "16"
/* 将属性值修改成自己的 VMware 的版本,我这里用的是16 */
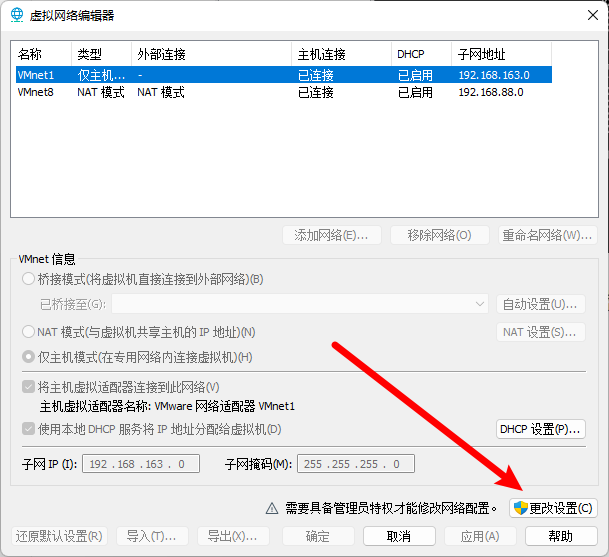
附录2:配置虚拟机的静态IP
建议:不需要额外配置虚拟机的静态IP。如要配置按下以下步骤操作:
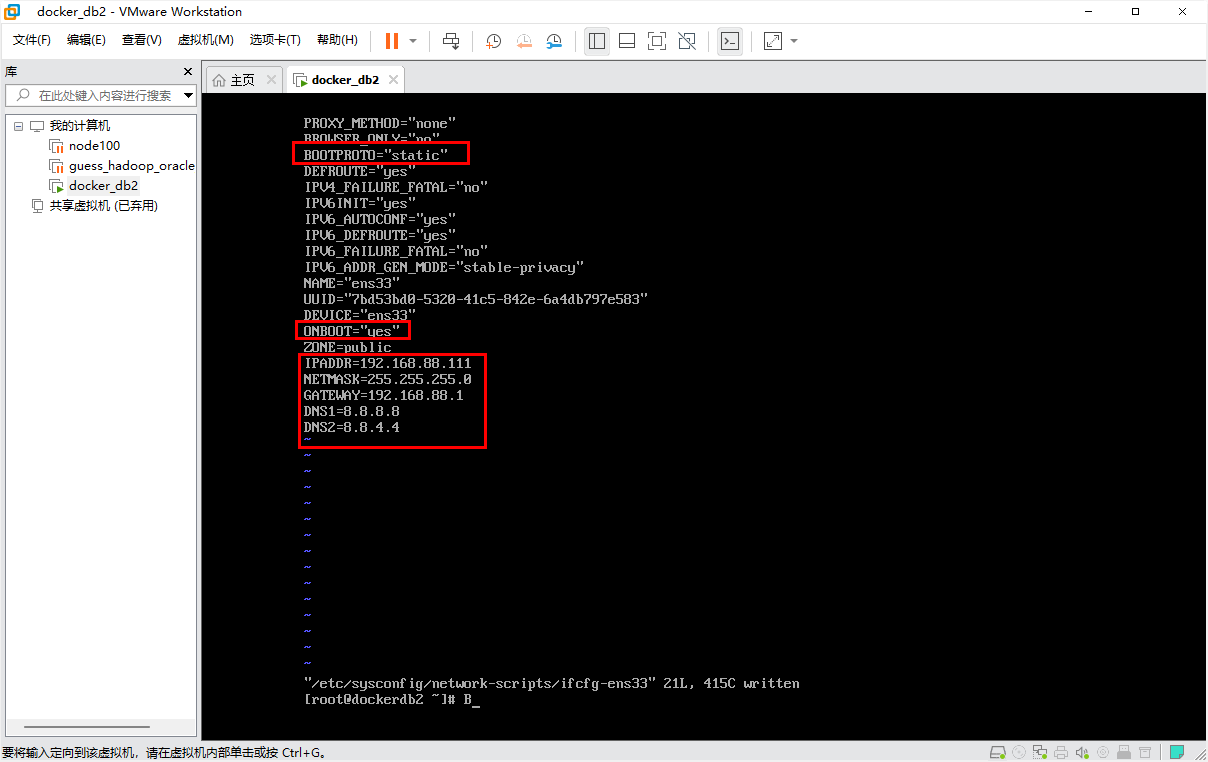
步骤1:输入命令 vim /etc/sysconfig/network-scripts/ifcfg-ens33 修改网络配置文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
修改:BOOTPROTO=static
修改:ONBOOT=yes
新增:IPADDR=192.168.88.111
新增:NETMASK=255.255.255.0
新增:GATEWAY=192.168.88.1
新增:DNS1=8.8.8.8
新增:DNS2=8.8.4.4
名词解释:
BOOTPROTO=static:设置为静态IP地址。
ONBOOT=yes:确保在启动时加载此配置。
IPADDR:设置为所需的IP地址。
NETMASK:设置为子网掩码。
GATEWAY:设置为网关地址。
DNS1和DNS2:设置为首选和备用DNS服务器。
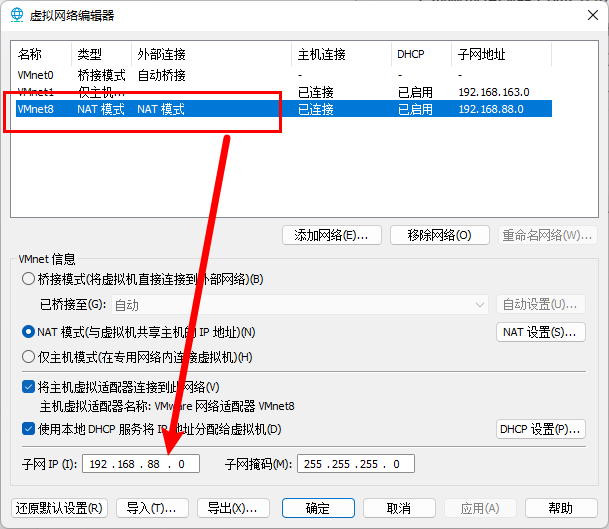
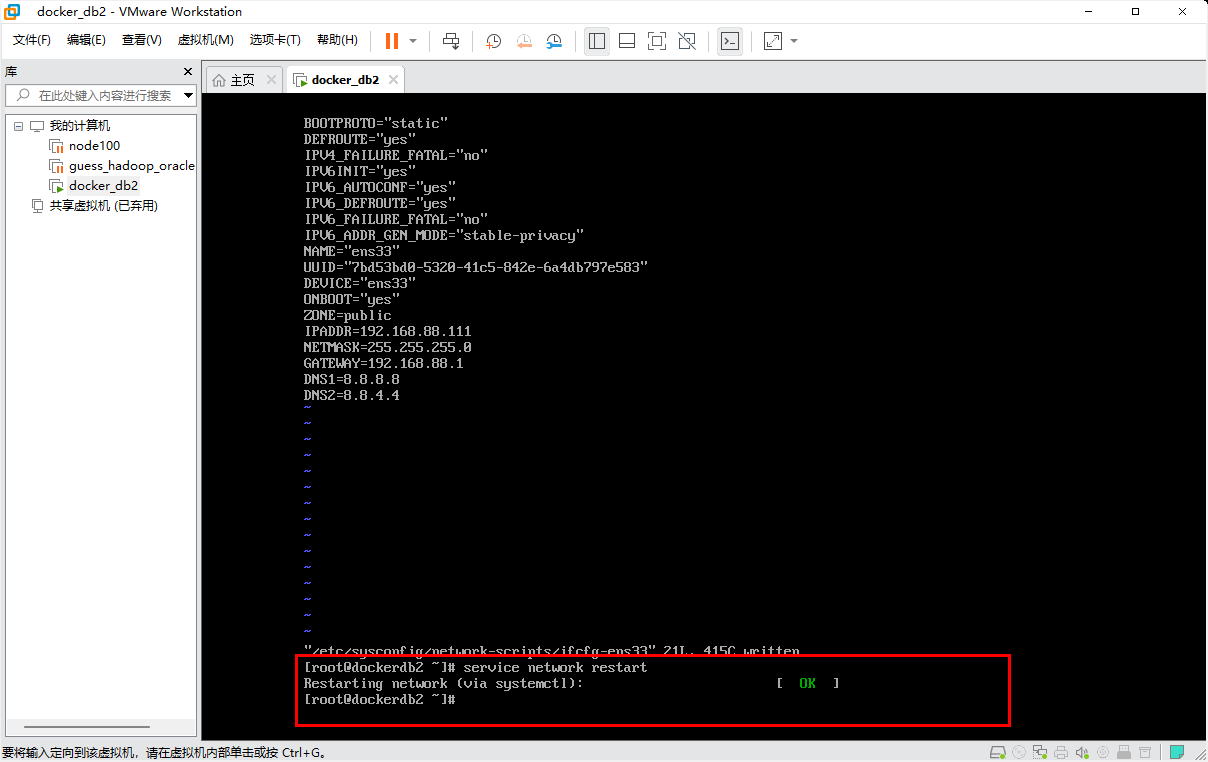
步骤2:修改完成后,执行命令 service network restart 重启网络服务后,并通过 ifconfig 命令查看 IP 是否和刚刚添加的 IP 是否一致。
步骤3:选择 VMware 左上角的”编辑” ==> “虚拟网络编辑器” ==> “更改设置” ==> “选择 VMnet8” ==> 修改子网 IP 网段(和Linux系统中设置的静态IP属于同一个网段) ==> 应用 ==> 确定。