Oracle数据库 开窗函数
1. 开窗函数
1.1 概述
什么是开窗函数?
- 开窗函数是一种能在 不合并数据行 的情况下,对数据进行分组统计(如排名、求和、平均等)的工具。它会给每一行数据”额外计算” 一个结果(比如排名、组内总和),但不会像
GROUP BY那样把一组数据合并成一行。
为什么要用开窗函数?
- 保留原始数据行
- 不像
GROUP BY会把一组数据”压缩” 成一行,而是给每行都算一个统计结果。
- 不像
- 分组统计不合并
- 可以按某个条件(如部门、班级)分组计算,但每组的结果会”附着” 在组内的每一行上。
- 多样的统计功能
- 不仅能算平均、总和,还能排名(比如谁是部门工资最高的)、取前后行数据(比如当前员工的前一名入职员工是谁)等。
举例:假设有一张”员工表”包含以下数据
| 姓名 | 部门 | 工资 | 入职时间 |
|---|---|---|---|
| 张三 | 开发部 | 10000 | 2020-01 |
| 李四 | 开发部 | 15000 | 2021-02 |
| 王五 | 销售部 | 8000 | 2019-03 |
如果用普通的GROUP BY按部门分组算平均工资
1
2
3
4
-- 普通聚合函数的局限(会"合并行")
SELECT 部门, avg(工资) AS 平均工资
FROM 员工表
GROUP BY 部门
结果会是:
| 部门 | 平均工资 |
|---|---|
| 开发部 | 12500 |
| 销售部 | 8000 |
问题:原来的每行数据(张三、李四、王五的个人信息)都没了,只剩下分组后的两行,无法看到每个人的工资和部门平均工资的对比。
如果使用开窗函数就可以让每行数据 既保留自己的信息,又显示所在组的统计结果,比如:
| 姓名 | 部门 | 工资 | 部门平均工资 |
|---|---|---|---|
| 张三 | 开发部 | 10000 | 12500 |
| 李四 | 开发部 | 15000 | 12500 |
| 王五 | 销售部 | 8000 | 8000 |
这里的”部门平均工资” 就是开窗函数算出来的,每行都有自己的结果,而且:
- 没有改变原来的行数(还是 3 行)。
- 按部门分组计算(开发部、销售部分别算平均),但没合并行。
开窗函数的优势:保留每行,附加统计结果
1.2 开窗函数分类
常见的开窗函数分类:
- 排名函数(给数据分组排名):
ROW_NUMBER()、RANK()、DENSE_RANK()ROW_NUMBER():连续排名(1,2,3,4…),相同值不重复。RANK():并列排名,有空缺(比如两个第 1 名,下一个是第 3 名)。DENSE_RANK():并列排名,无空缺(两个第 1 名,下一个是第 2 名)。
- 聚合类开窗函数(在窗口内做聚合计算):
SUM()、AVG()、MAX()、MIN()、COUNT()- 比如计算每个员工的工资在部门内的累计总和、平均工资等。
- 位置偏移函数:
LAG()、LEAD()- 用来获取当前行前后某一行的数据(比如比较当前月和上个月的销售额)。
1.3 开窗函数语法
开窗函数的语法:
1
函数名称 OVER( [PARTITION BY 分组列] [ORDER BY 排序列] [窗口范围] )
可以拆成三个部分:
-
PARTITION BY:分组(确定”窗口” 属于哪个组)
1 2 3 4
比如按"部门" 分组,每个部门就是一个"小窗口",开窗函数只会在这个部门内的数据里计算。 例子:PARTITION BY 部门 表示按部门分组,开发部的员工只和开发部的人一起算平均工资,销售部的人只和销售部的人算。
-
ORDER BY:排序(组内数据的顺序)
1 2 3 4
比如按"工资" 从高到低排序,决定了在计算排名、移动平均等时数据的顺序。 例子:ORDER BY 工资 DESC 表示在分组内按工资从高到低排,这样排名函数就知道谁是第一名、第二名。
-
窗口范围(可选,定义计算时包含哪些数据)
1 2 3
比如"当前行的前1行和后1行",或者"从组内第一行到当前行"。如果不写,默认是"从组内第一行到当前行"。 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING,表示计算时包含当前行、前一行、后一行(共3行的数据。
1.4 开窗函数的应用
前置数据准备:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
-- 模拟银行业务:customers(客户表)、accounts(账户表)、transactions(交易表)
-- 创建客户表
CREATE TABLE customers (
customer_id NUMBER PRIMARY KEY,
customer_name VARCHAR2(100),
customer_city VARCHAR2(100)
);
-- 创建账户表
CREATE TABLE accounts (
account_id NUMBER PRIMARY KEY,
customer_id NUMBER,
account_type VARCHAR2(50),
balance NUMBER
);
-- 创建交易表
CREATE TABLE transactions (
transaction_id NUMBER PRIMARY KEY,
account_id NUMBER,
transaction_date DATE,
amount NUMBER
);
-- 插入客户数据
INSERT INTO customers (customer_id, customer_name, customer_city) VALUES (1, 'Alice', 'New York');
INSERT INTO customers (customer_id, customer_name, customer_city) VALUES (2, 'Bob', 'Los Angeles');
INSERT INTO customers (customer_id, customer_name, customer_city) VALUES (3, 'Charlie', 'Chicago');
-- 插入账户数据
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (101, 1, 'Checking', 5000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (102, 1, 'Savings', 10000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (103, 2, 'Checking', 3000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (104, 2, 'Savings', 8000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (105, 3, 'Checking', 2000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (106, 3, 'Savings', 6000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (107, 3, 'Savings', 2000);
INSERT INTO accounts (account_id, customer_id, account_type, balance) VALUES (108, 1, 'Savings', 10000);
-- 插入交易数据
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (1, 101, TO_DATE('2024-01-01', 'YYYY-MM-DD'), 1000);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (2, 101, TO_DATE('2024-01-02', 'YYYY-MM-DD'), -500);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (3, 102, TO_DATE('2024-01-03', 'YYYY-MM-DD'), 2000);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (4, 103, TO_DATE('2024-01-04', 'YYYY-MM-DD'), 500);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (5, 103, TO_DATE('2024-01-05', 'YYYY-MM-DD'), -200);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (6, 104, TO_DATE('2024-01-06', 'YYYY-MM-DD'), 1000);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (7, 105, TO_DATE('2024-01-07', 'YYYY-MM-DD'), 300);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (8, 105, TO_DATE('2024-01-08', 'YYYY-MM-DD'), -100);
INSERT INTO transactions (transaction_id, account_id, transaction_date, amount) VALUES (9, 106, TO_DATE('2024-01-09', 'YYYY-MM-DD'), 1500);
1.4.1 排名函数
在 Oracle 数据库里,开窗函数中的排名函数能够按照特定规则对查询结果里的行进行排名操作。
常见的排名函数:ROW_NUMBER()、RANK() 和 DENSE_RANK()。
1.4.1.1 ROW_NUMBER
功能:为结果集里的每一行分配一个唯一的连续整数排名。不管是否存在相同的值,排名都是连续递增的。
语法:
1
2
3
4
ROW_NUMBER() OVER (
[PARTITION BY 分组列, ... ]
ORDER BY 排序列 [ASC | DESC], ...
)
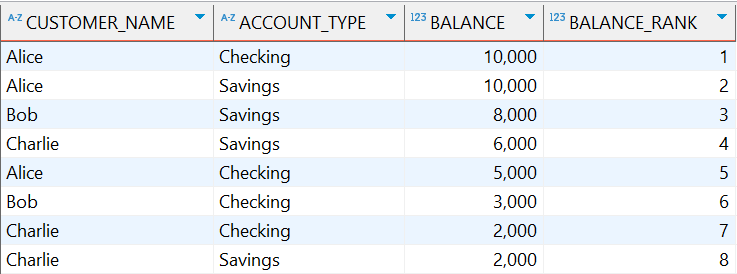
示例:按账户余额对客户进行排名
1
2
3
4
5
6
7
8
9
SELECT
c.customer_name,
a.account_type,
a.balance,
ROW_NUMBER() OVER (ORDER BY a.balance DESC) as balance_rank
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id;
-
执行结果:
1.4.1.2 RANK
功能:为结果集里的行分配排名,若存在相同的值,则这些行排名相同,且下一个排名会跳过相应的名次。
语法:
1
2
3
4
RANK() OVER (
[PARTITION BY 分组列, ... ]
ORDER BY 排序列 [ASC | DESC], ...
)
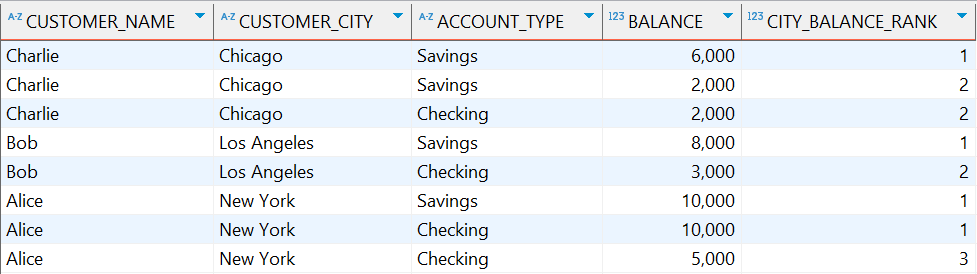
示例:按城市分组,对每个城市的客户账户余额进行排名
1
2
3
4
5
6
7
8
9
10
SELECT
c.customer_name,
c.customer_city,
a.account_type,
a.balance,
RANK() OVER (PARTITION BY c.customer_city ORDER BY a.balance DESC) as city_balance_rank
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id;
-
执行结果:
1.4.1.3 DENSE_RANK
功能:为结果集里的行分配排名,若存在相同的值,则这些行排名相同,且下一个排名是连续的,不会跳过名次。
语法:
1
2
3
4
DENSE_RANK() OVER (
[PARTITION BY 分组列, ... ]
ORDER BY 排序列 [ASC | DESC], ...
)
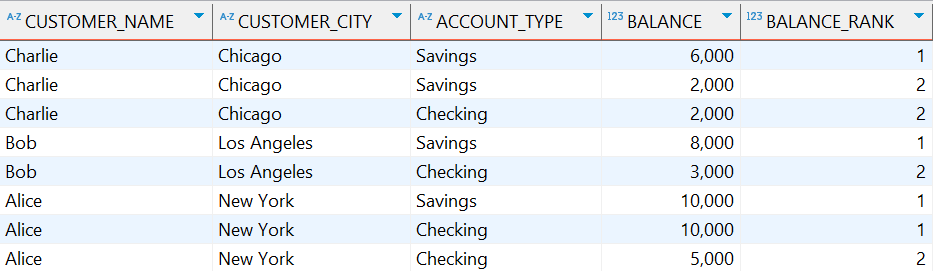
示例:按账户余额对每个城市的客户账户进行排名
1
2
3
4
5
6
7
8
9
10
SELECT
c.customer_name,
c.customer_city,
a.account_type,
a.balance,
DENSE_RANK() OVER (PARTITION BY c.customer_city ORDER BY a.balance DESC) as balance_rank
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id;
-
执行结果:
1.4.2 聚合开窗函数
在 Oracle 数据库里,聚合开窗函数是一种非常实用的工具,它能够在不改变原始查询结果行数的基础上,对特定分组内的数据进行聚合计算。
常用的聚合计算:SUM、MAX、MIN、AVG、COUNT
1.4.2.1 SUM
功能:对指定分组内的某列值进行求和操作。
语法:
1
2
3
4
5
SUM(column_name) OVER (
[PARTITION BY 分组列, ... ]
[ORDER BY 排序列 [ASC | DESC], ... ]
[窗口范围]
)
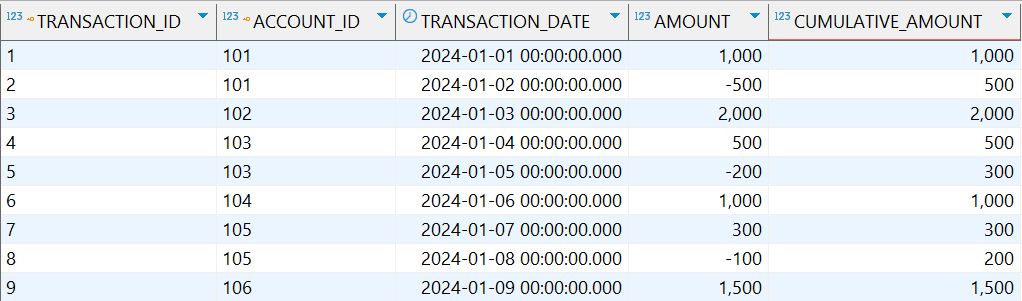
示例:计算每个客户账户的累计交易金额
1
2
3
4
5
6
7
8
9
10
SELECT
t.transaction_id,
a.account_id,
t.transaction_date,
t.amount,
SUM(t.amount) OVER (PARTITION BY a.account_id ORDER BY t.transaction_date) as cumulative_amount
FROM
accounts a
JOIN
transactions t ON a.account_id = t.account_id;
解释:PARTITION BY account_id将结果集按账户id分组,ORDER BY transaction_date在每个账户组内按交易日期排序,SUM(amount)对每个分组内按排序顺序的交易金额进行累计求和。
-
执行结果:
1.4.2.2 AVG
功能:计算指定分组内某列值的平均值。
语法:
1
2
3
4
5
AVG(column_name) OVER (
[PARTITION BY 分组列, ... ]
[ORDER BY 排序列 [ASC | DESC], ... ]
[窗口范围]
)
示例:计算每个城市所有客户账户的平均余额
1
2
3
4
5
6
7
8
9
10
SELECT
c.customer_name,
c.customer_city,
a.account_type,
a.balance,
AVG(a.balance) OVER (PARTITION BY c.customer_city) as city_avg_balance
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id;
-
执行结果:
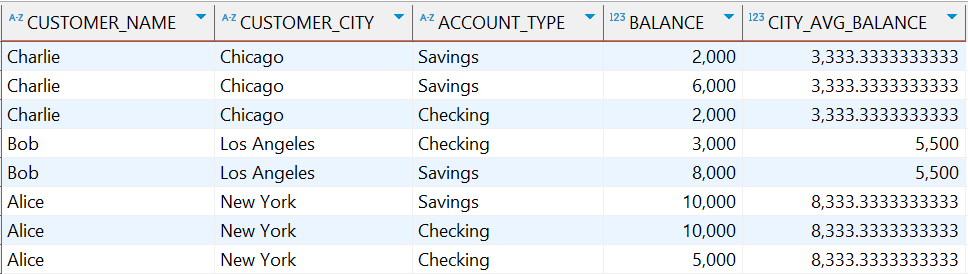
1.4.2.3 MAX
功能:找出指定分组内某列值的最大值。
语法:
1
2
3
4
5
MAX(column_name) OVER (
[PARTITION BY 分组列, ... ]
[ORDER BY 排序列 [ASC | DESC], ... ]
[窗口范围]
)
示例:计算每个客户账户的最大交易金额
SELECT
t.transaction_id,
a.account_id,
c.customer_name,
t.amount,
MAX(t.amount) OVER (PARTITION BY a.account_id) as max_transaction_amount
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id
JOIN
transactions t ON a.account_id = t.account_id;
-
执行结果:
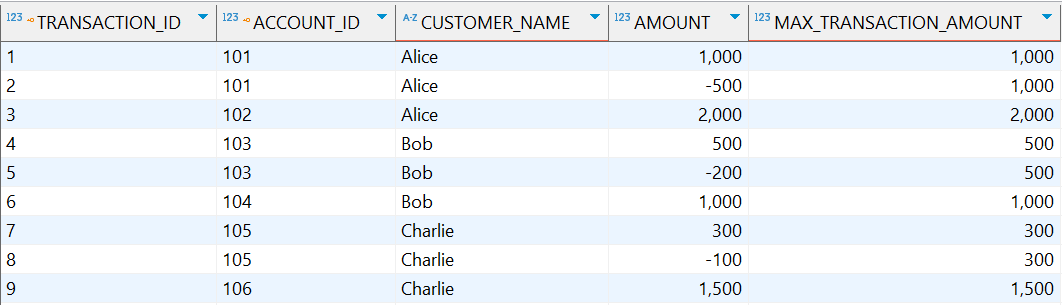
1.4.2.4 MIN
功能:找出指定分组内某列值的最小值。
语法:
1
2
3
4
5
AVG(column_name) OVER (
[PARTITION BY 分组列, ... ]
[ORDER BY 排序列 [ASC | DESC], ... ]
[窗口范围]
)
示例:计算每个客户账户的最小交易金额
1
2
3
4
5
6
7
8
9
10
11
12
SELECT
t.transaction_id,
a.account_id,
c.customer_name,
t.amount,
MIN(t.amount) OVER (PARTITION BY a.account_id) as min_transaction_amount
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id
JOIN
transactions t ON a.account_id = t.account_id;
-
执行结果:
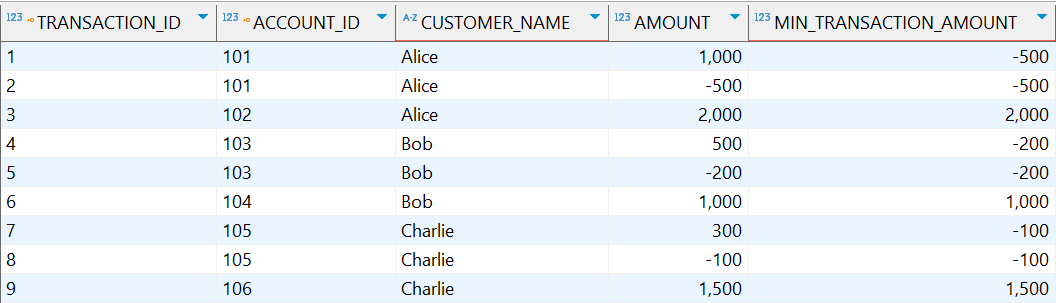
1.4.2.5 COUNT
功能:统计指定分组内的行数或非空值的数量。
语法:
1
2
3
4
5
COUNT(column_name) OVER (
[PARTITION BY 分组列, ... ]
[ORDER BY 排序列 [ASC | DESC], ... ]
[窗口范围]
)
示例:统计每个城市的客户账户数量
1
2
3
4
5
6
7
SELECT
c.customer_city,
a.account_id,
COUNT(a.account_id) OVER (PARTITION BY c.customer_city) as account_count
FROM
customers c
JOIN accounts a ON c.customer_id = a.customer_id;
-
执行结果:
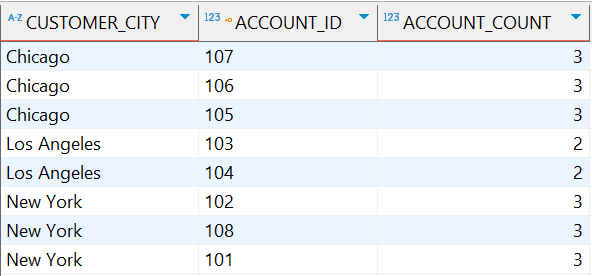
1.4.2.5 LISTAGG
在 Oracle 数据库里,LISTAGG() 是一个聚合函数,通常和 WITHIN GROUP 子句搭配使用,而 OVER 子句一般用于窗口函数。
LISTAGG() 函数的基本功能:用于把多行数据合并成一个字符串。
基本语法如下:
1
LISTAGG(column, delimiter) WITHIN GROUP (ORDER BY sort_column)
column:要合并的列delimiter:合并结果里用于分隔元素的分隔符,比如逗号,、分号;等sort_column:用于对要合并的数据进行排序的列
示例:
1
2
3
4
5
6
7
8
-- 使用 LISTAGG() WITHIN GROUP() 把每个客户的交易流水金额合并为一个字符串
SELECT
account_id,
LISTAGG(amount, ' , ') WITHIN GROUP (ORDER BY amount) AS amount_list
FROM
transactions
GROUP BY
account_id;
LISTAGG() 结合 OVER 子句
1
2
LISTAGG(column, delimiter) WITHIN GROUP (ORDER BY sort_column)
OVER (PARTITION BY 分区列)
虽然 LISTAGG() 并非传统意义上的窗口函数,但也能结合 OVER 子句使用。不过需要注意,这会返回一个结果集,其中每行都会重复显示合并后的字符串。
示例:对于每个客户,列出其所有交易金额,以竖线分隔
1
2
3
4
5
6
7
8
9
10
11
SELECT
c.customer_id,
c.customer_name,
LISTAGG(t.amount, ' | ') WITHIN GROUP (ORDER BY t.transaction_date)
OVER (PARTITION BY c.customer_id) AS transaction_amounts
FROM
customers c
JOIN
accounts a ON c.customer_id = a.customer_id
JOIN
transactions t ON a.account_id = t.account_id;
-
执行结果:返回的结果集,其中每行都会重复显示合并后的字符串
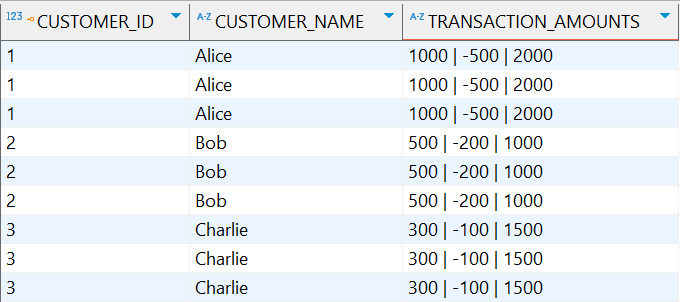
1.4.3 位置偏移函数
在 Oracle 数据库里,开窗函数中的位置偏移函数可以帮助我们在查询结果集里获取当前行前后特定偏移位置的行的数据,主要有 LAG() 和 LEAD() 这两个函数。
1.4.3.1 LAG
功能:LAG() 函数用于从当前行向前(即前几行)获取指定列的值。可以在当前行的基础上,访问之前行的数据,这在对比当前行和之前行的数据差异时非常有用。例如:比较相邻时间段的销售额、查看员工工资的历史变化等。
语法:
1
2
3
4
LAG(column_name, offset, default_value) OVER (
[PARTITION BY 分组列, ... ]
ORDER BY 排序列 [ASC | DESC], ...
)
column_name:需要获取值的列名。offset:偏移量,表示要向前获取的行数,默认值为 1,也就是获取前一行的值。default_value:可选参数,当偏移位置超出结果集范围时返回的值,若不指定,默认返回NULL。PARTITION BY:可选参数,用于将结果集按指定列进行分组,函数会在每个分组内独立进行偏移操作。ORDER BY:指定结果集的排序顺序,偏移操作会按照这个顺序进行。
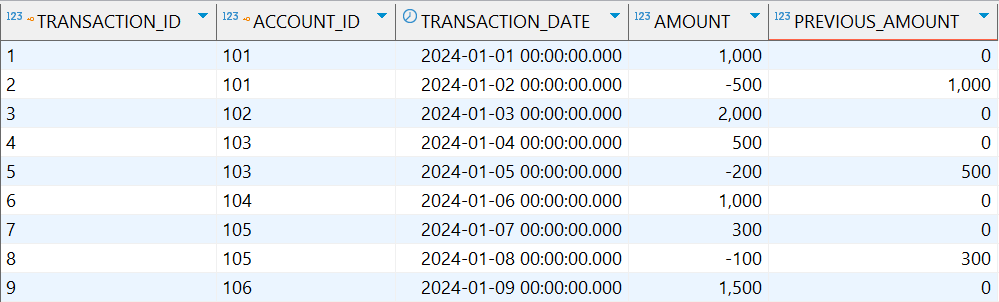
示例:获取每个账户上一笔交易的金额
1
2
3
4
5
6
7
8
9
10
SELECT
t.transaction_id,
a.account_id,
t.transaction_date,
t.amount,
LAG(t.amount, 1, 0) OVER (PARTITION BY a.account_id ORDER BY t.transaction_date) as previous_amount
FROM
accounts a
JOIN
transactions t ON a.account_id = t.account_id;
-
执行结果:
1.4.3.2 LEAD
功能:LEAD() 函数与 LAG() 函数相反,用于从当前行向后(即后第几行)获取指定列的值。这在预测未来数据、查看后续时间段的变化等场景中很有用。例如:分析销售额的增长趋势。
语法:
1
2
3
4
LEAD(column_name, offset, default_value) OVER (
[PARTITION BY 分组列, ... ]
ORDER BY 排序列 [ASC | DESC], ...
)
- 其参数含义与
LAG()函数相同。
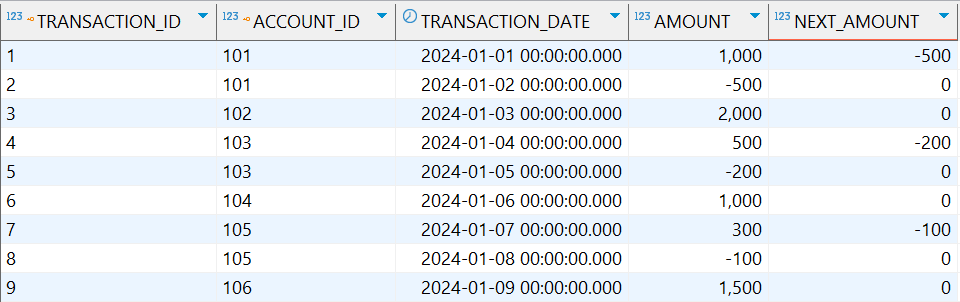
示例:获取每个账户下一笔交易的金额
1
2
3
4
5
6
7
8
9
10
SELECT
t.transaction_id,
a.account_id,
t.transaction_date,
t.amount,
LEAD(t.amount, 1, 0) OVER (PARTITION BY a.account_id ORDER BY t.transaction_date) as next_amount
FROM
accounts a
JOIN
transactions t ON a.account_id = t.account_id;
-
执行结果:
思考问题:如何使用开窗函数优化Oracle中的分页查询
之前学习的内容:使用
rownum+子查询实现分页查询
- 当查询时有排序的情况下,会书写三层SELECT查询(检索数据的效率会很低)