Oracle数据库 常见函数, 集合运算, 行列转换
回顾上次课程内容:
-
多表关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
多表关系有3种: 1、一对一 2、一对多 3、多对多 一对一关系: 在任意一张表上新增字段(外键),和另外一张表中的主键列进行关联(多表查询时条件关联) 一对多关系: 在属于"多"的表上新增字段(外键),和"一"表中的主键列进行关联 多对多关系: 创建第三张中间表,由中间表把复杂的多对多关系拆分为两个一对多,在中间表上分别新增两个外键字段,去关联另外两张表中的主键字段。 例如: 学生表和课程表 (多对多关系) 创建中间表: 学生课程关系表 分别有三个字段:id、学生id(外键)、课程id(外键) 学生表 vs 学生课程关系表 一对多 课程表 vs 学生课程关系表 一对多 -
多表查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
-- 内连接查询 表A[id]、表B[uid]、表C[uid] SELECT 字段..... FROM 表A JOIN 表B ON 表A.id = 表B.uid JOIN 表C ON 表A.id = 表C.uid -- 左外连接查询 左表[id]、右表[uid] SELECT 字段.... FROM 左表 LEFT JOIN 右表 ON 左表.id = 右表.uid SELECT 字段.... FROM 左表 , 右表 WHERE 左表.id = 右表.uid(+) -- 核心表不使用(+) 从表上添加:(+) -- 右外连接查询 SELECT 字段.... FROM 左表 RIGHT JOIN 右表 ON 左表.id = 右表.uid -- 全外连接查询 = 左外连接 + 右外连接 SELECT 字段.... FROM 左表 FULL JOIN 右表 ON 左表.id = 右表.uid -- 自然连接查询(了解) SELECT 字段.... FROM 表A NATURAL JOIN 表B -- 连表查询:表A和表B中字段名相同且数据类型相同 SELECT 字段 ... FROM 表A JOIN 表B USING(两表中相同字段)
-
子查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- 子查询书写在where子句 select ... from 表1 where 字段 = (select 字段 from 表 where 条件) -- 子查询书写在from子句 select 表别名.字段1, 表别名.字段2, ... from (select ... from 表 where 条件) 表别名 -- 子查询书写在having子句 select ..... from 表 group by 分组字段 having 字段 > (select ... from 表名 where 条件) -- 子查询书写在select子句(子查询结果通常仅有一行一列) select 字段1, (select ... from 表名 where 列名1=字段2) from 表名 where 条件
-
伪列
1 2 3 4 5 6
-- 伪列:由oracle数据库自己维护管理的列,每张表中都有伪列存在,只能进行select查询使用,使用时必须显式书写伪列的名字: select rowid, t.* from 表 t select * from 表名 where rownum<=10 -- rowid : 数据表中每一行记录的物理地址 通过rowid可以快速的查询某一行记录 -- rownum : 数据表中每一行记录的行号 -- 产生时机:查询时oracle会对数据表进行扫描,扫描到每一行记录时,oracle就会给当前扫描到的行中的rownum伪列指定一个当前行的标识(行号)
-
分页查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- 没有排序的分页查询 select * from (select rownum AS rm , t.* from 表 t where rownum<=30) where rm > 20 -- 有排序的分页查询 select * from (select rownum AS rm , t.* from (select * from 表 order by 排序字段 排序规则) t where rownum<=30) where rm > 20
0. 函数概述
在 Oracle 数据库里,函数就像是一个小工具,给它一些输入内容,它会按照特定的规则处理这些输入内容,然后返回一个输出结果。
什么是函数?
函数本质上是一段已经编写好的代码块,被封装起来并起了个名字。当在 SQL 语句里使用这个函数名,同时提供它所需要的输入(也就是参数),函数就会执行预先定义好的操作,最后返回一个结果。
举个例子:ROUND 函数就是用来对数字进行四舍五入的。给它一个数字和想要保留的小数位数,它就会返回四舍五入后的结果。
1
ROUND(3.14159, 2) : 会把 3.14159 四舍五入到小数点后两位,返回3.14
函数的作用:
- 数据处理和转换:函数能对数据进行各种处理和转换,让数据更符合我们的需求。如:日期字符串”2024-01-01”,使用
TO_DATE('2024-01-01','YYYY-MM-DD')就能把它转换为日期类型。 - 数据计算和统计:聚合函数可以对数据进行计算和统计。如:
AVG函数可以计算某列数据的平均值。 - 条件判断和筛选:有些函数可以进行条件判断,筛选出符合特定条件的数据。如:
CASE函数,它可以根据不同的条件返回不同的结果。
在Oracle 数据库里函数主要分为以下几类:
- 单行函数(今天学习)
- 聚合函数(已学习)
- 分析函数(后续课程学习)
- 结合了单行函数和聚合函数的特点,既可以对每行数据进行处理,又能基于一组数据计算结果。
1. 字符函数
| 函 数 | 说明 |
|---|---|
| ASCII | 返回对应字符的十进制值 |
| CHR | 给出十进制返回字符 |
| CONCAT | 拼接两个字符串,与 || 相同 |
| INITCAP | 将字符串的第一个字母变为大写 |
| INSTR | 找出某个字符串的位置 |
| INSTRB | 找出某个字符串的位置和字节数 |
| LENGTH | 以字符给出字符串的长度 |
| LENGTHB | 以字节给出字符串的长度 |
| LOWER | 将字符串转换成小写 |
| LPAD | 使用指定的字符在字符的左边填充 |
| LTRIM | 在左边裁剪掉指定的字符 |
| RPAD | 使用指定的字符在字符的右边填充 |
| RTRIM | 在右边裁剪掉指定的字符 |
| REPLACE | 执行字符串搜索和替换 |
| SUBSTR | 取字符串的子串 |
| SUBSTRB | 取字符串的子串(以字节) |
| SOUNDEX | 返回一个同音字符串 |
| TRANSLATE | 执行字符串搜索和替换 |
| TRIM | 裁剪掉前面或后面的字符串 |
| UPPER | 将字符串变为大写 |
示例1:求字符串长度length
1
2
SELECT length('bigdata') FROM dual;
-- 说明:dual是oracle的内部表(虚表),表中仅有一行一列。 作用:为配合oracle语法而存在。
示例2:字符串拼接CONCAT
1
2
3
4
5
-- concat('字符串','字符串')
SELECT concat('Big','Data') FROM dual;
-- 可以用 || 对字符串进行拼接
SELECT 'Big' || 'Data' FROM dual;
示例3:字符串替换REPLACE
1
SELECT replace('Linux-MySQL-Hadoop','MySQL','Oracle') FROM dual;
请问
SELECT replace('Hadoop','o') FROM dual执行结果?
示例4:字符串全部转换成小写/大写
1
2
3
4
5
-- 转小写
SELECT lower('HADOOP') FROM dual;
-- 转大写
SELECT upper('hadoop') FROM dual;
示例5:求字符串的子串SUBSTR
1
2
-- substr(字符串,起始位置,截取长度)
SELECT substr('Linux-Oracle-Hadoop',7,6) FROM dual;
以下查询执行完后,结果是什么?
面试题:请问substr()函数截取时下标是从0还是从1开始?
- 对ORACLE来讲,substr下标从0或从1都不会有问题,而且下标还可写成负数形式,表示从后向取值
2. 数值函数
| 函数 | 说明 |
|---|---|
| ABS(value) | 绝对值 |
| CEIL(value) | 大于或等于value的最小整数 |
| COS(value) | 余弦 |
| COSH(value) | 反余弦 |
| EXP(value) | e的value次幂 |
| FLOOR(value) | 小于或等于value的最大整数 |
| LN(value) | value的自然对数 |
| LOG(value) | value的以10为底的对数 |
| MOD(value,divisor) | 求模 |
| POWER(value,exponent) | value的exponent次幂 |
| ROUND(value,precision) | 按precision 精度4舍5入 |
| SIGN(value) | value为正返回1;为负返回-1;为0返回 0. |
| SIN(value) | 正弦 |
| SINH(value) | 反正弦 |
| SQRT(value) | value 的平方根 |
| TAN(value) | 正切 |
| TANH(value) | 反正切 |
| TRUNC(value,按precision) | 按照precision 截取value |
| VSIZE(value) | 返回value在ORACLE的存储空间大小 |
示例1:四舍五入函数ROUND
1
2
3
4
5
-- round(数值)
SELECT round(100.567) FROM dual;
-- round(数值,小数位数)
SELECT round(100.567,2) FROM dual;
示例2:截取函数TRUNC
1
2
3
4
5
-- trunc(数值) 不会四舍五入,直接截断
SELECT trunc(100.567) FROM dual;
-- trunc(数值,小数位数)
SELECT trunc(100.567,2) FROM dual;
示例3:取模 MOD
1
SELECT mod(10,3) FROM dual;
3. 日期函数
| 函 数 | 描述 |
|---|---|
| ADD_MONTHS(date,count) | 在日期date上增加count个月(count可为负数) |
| GREATEST(date1,date2,. . .) | 从日期列表中选出最晚的日期 |
| LAST_DAY( date ) | 返回日期date 所在月的最后一天 |
| LEAST( date1, date2, . . .) | 从日期列表中选出最早的日期 |
| MONTHS_BETWEEN(date2,date1) | 给出 date2 - date1 的月数(可以是小数) |
| NEXT_DAY( date,’day’) | 给出日期date之后下一天的日期,这里的day为星期,如: MONDAY,Tuesday等。 |
| NEW_TIME(date,’this’,’other’) | 给出在this 时区=Other时区的日期和时间 |
| ROUND(date,’format’) | 未指定format时,如果日期中的时间在中午之前,则将日期中的时间截断为12 A.M.(午夜,一天的开始),否则进到第二天。 |
| TRUNC(date,’format’) | 未指定format时,将日期截为12 A.M.( 午夜,一天的开始). |
用sysdate这个系统变量来获取当前系统的日期和时间
1
SELECT sysdate FROM dual;
示例1:在日期基础上加指定的月 - 加月函数 ADD_MONTHS
1
2
3
4
SELECT add_months(sysdate,2) FROM dual;
-- 执行下面SQL语句会显示什么?
SELECT add_months(sysdate,-2) FROM dual; -- 在当前日期的基础上,向前推2个月(减月)
示例2:求所在月最后一天LAST_DAY
1
SELECT last_day(sysdate) FROM dual;
示例3:求两个日期相差多少个月
1
SELECT months_between(sysdate,to_date('20250120','yyyyMMdd')) FROM dual;
示例4:日期截取TRUNC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 截掉时间值,保留日期值
SELECT trunc(sysdate) FROM dual;
-- 按年截取(保留年份、月和日为初始值1)
SELECT trunc(sysdate,'yyyy') FROM dual;
-- 按月截取(保留年月,日的初始值为1)
SELECT trunc(sysdate,'mm') FROM dual;
-- 按日截取(保留年月日,时分秒的初始值为0)
SELECT trunc(sysdate,'dd') FROM dual;
-- 按时截取(保留年月日时,分秒的初始值为0)
SELECT trunc(sysdate,'hh') FROM dual;
-- 按分截取(保留年月日时分,秒的初始值为0)
SELECT trunc(sysdate,'mi') FROM dual;
回顾上午学习的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
select length('abcd') from dual;
select concat('aaa','bbb') from dual; select 'abc'||'xyz' from dual;
select replace('hadoop','o','X') from dual; -- o替换x
select replace('hadoop','o') from dual; -- 删除字符串内的o字符
select substr('hadoop',2,3) from dual
select lower('Hadoop') from dual;-- 转小写
select upper("hadoop") from dual; -- 转大写
select round(100.567) from dual; -- 四舍五入取整
select round(100.567,2) from dual; -- 四舍五入取小数
select trunc(100.567) from dual; -- 截断取整
select trunc(100.567,2) from dual;-- 按小数位截断
select add_months(日期, 2) from dual; --在指定日期基础上添加2个月
select last_day(日期) from dual;-- 获取指定日期所有月份的最后一天
select months_between(日期1,日期2) from dual; --获取两个日期之间相差几个月
select trunc(日期) from dual; -- 截取日期中的年月日
select trunc(日期,'mi') from dual; -- 保留年月日时分,秒和毫秒全部是0
-- 2025-04-28 14:16:23:1234 => 2025-04-28 14:16:00:0000
4. 转换函数
| 函 数 | 描 述 |
|---|---|
| CHARTOROWID | 将 字符转换到 rowid类型 |
| CONVERT | 转换一个字符节到另外一个字符节 |
| HEXTORAW | 转换十六进制到raw 类型 |
| RAWTOHEX | 转换raw 到十六进制 |
| ROWIDTOCHAR | 转换 ROWID到字符 |
| TO_CHAR | 转换日期格式到字符串 |
| TO_DATE | 按照指定的格式将字符串转换到日期型 |
| TO_MULTIBYTE | 把单字节字符转换到多字节 |
| TO_NUMBER | 将数字字串转换到数字 |
| TO_SINGLE_BYTE | 转换多字节到单字节 |
示例1:数字转字符串TO_CHAR
1
2
3
4
5
-- 把数据转换为字符串
SELECT to_char(1024) FROM dual; -- '1024'
-- 把数字按照指定格式转换为字符串
SELECT to_char(123456789,'000,000,000') FROM dual;
示例2:日期转字符串TO_CHAR
1
2
3
4
5
6
7
8
9
10
11
12
-- 把日期按照指定格式转换为字符串
SELECT to_char(sysdate,'yyyy-mm-dd') FROM dual;
SELECT to_char(sysdate,'yyyy-mm-dd hh:mi:ss') FROM dual;
-- 24小时制
SELECT to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') FROM dual;
SELECT to_char(sysdate,'hh24:mi:ss') FROM dual;
-- 转换时去除0
SELECT to_char(sysdate,'yyyy-fmmm-fmdd fmhh24:fmmi:fmss') FROM dual;
-- 带中文的日期格式
SELECT to_char(sysdate,'yyyy"年"mm"月"dd"日" hh24"时"mi"分"ss"秒"') FROM dual;
使用
to_char(sysdate, 'HH')‘HH’可以使用如下表中的参数替换
模板 描述 HH 一天的小时数 (01-12) HH12 一天的小时数 (01-12) HH24 一天的小时数 (00-23) MI 分钟 (00-59) SS 秒 (00-59) SSSS 午夜后的秒 (0-86399) AM or A.M. or PM or P.M. 正午标识(大写) am or a.m. or pm or p.m. 正午标识(小写) Y,YYY 带逗号的年(4 和更多位) YYYY 年(4和更多位) YYY 年的后三位 YY 年的后两位 Y 年的最后一位 MONTH 全长大写月份名(9字符) Month 全长混合大小写月份名(9字符) month 全长小写月份名(9字符) MON 大写缩写月份名(3字符) Mon 缩写混合大小写月份名(3字符) mon 小写缩写月份名(3字符) MM 月份 (01-12) DAY 全长大写日期名(9字符) Day 全长混合大小写日期名(9字符) day 全长小写日期名(9字符) DY 缩写大写日期名(3字符) Dy 缩写混合大小写日期名(3字符) dy 缩写小写日期名(3字符) DDD 一年里的日子(001-366) DD 一个月里的日子(01-31) D 一周里的日子(1-7;SUN=1) W 一个月里的周数 WW 一年里的周数 CC 世纪(2 位) J Julian 日期(自公元前4712年1月1日来的日期) Q 季度
示例3:字符串转日期TO_DATE
1
2
-- 把字符串按照指定格式转换为日期
SELECT to_date('2020-07-10','yyyy-mm-dd') FROM dual;
示例4:字符串转数字TO_NUMBER
1
SELECT to_number('100') FROM dual;
5. 通用函数
空值处理函数 - NVL
用法: NVL(检测的值,如果为null的值)
语句:
1
select NVL(NULL,0) from dual
需求:显示价格表中业主类型ID为1的价格记录,如果上限值为NULL,则显示9999999
1
2
3
SELECT price,minnum,NVL(maxnum,9999999)
FROM t_pricetable
WHERE ownertypeid=1;
空值处理函数 - NVL2
用法:NVL2(检测的值,如果不为null的值,如果为null的值)
- 说明:需要保持为null时的值和不为null时的值属于同一种类型
需求:显示价格表中业主类型ID为1的价格记录,如果上限值为NULL,显示“不限”
1
2
3
SELECT price,minnum,NVL2(maxnum,to_char(maxnum),'不限')
FROM t_pricetable
WHERE ownertypeid=1;
条件取值 - decode
DECODE()函数:多数值判断,类似于if…else语句,不同的是decode()判断的是数值而不是逻辑条件
在SQL优化中,推荐使用DECODE(),可以减少I/O次数
语法:
1
2
-- 功能: 根据条件返回相应值
decode(条件, 值1,翻译值1, 值2,翻译值2,... 值n,翻译值n, 缺省值)
需求:显示下列信息(不要关联查询业主类型表,直接判断1 2 3 的值)
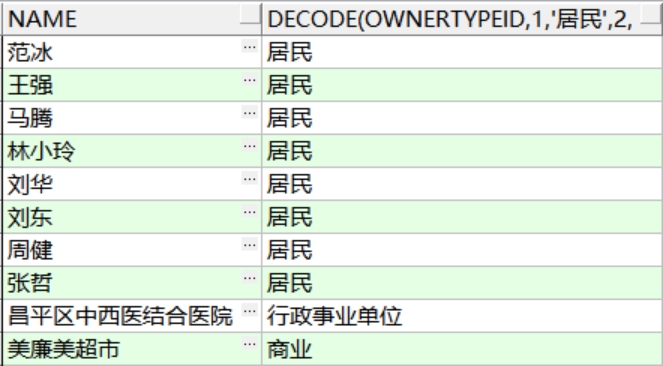
1
2
SELECT name,decode(ownertypeid,1,'居民',2,'行政事业单位',3,'商业') AS type
FROM t_owners;
上边的语句也可以用case when then 语句来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
-- 写法1:
SELECT
name,
(case ownertypeid
when 1 then '居民'
when 2 then '行政事业单位'
when 3 then '商业'
end
) AS type
FROM t_owners;
-- 写法2:
SELECT
name,
(case
when ownertypeid=1 then '居民'
when ownertypeid=2 then '行政事业单位'
when ownertypeid=3 then '商业'
else '其它'
end) AS type
FROM t_owners;
6. 集合运算
6.1 概述
什么是集合运算?
- 集合运算就是将两个或者多个结果集组合成为一个结果集。
集合运算包括:
-
UNION ALL(并集),返回各个查询的所有记录,包括重复记录。
-
UNION(并集),返回各个查询的所有记录,不包括重复记录。
-
INTERSECT(交集),返回两个查询共有的记录。
-
MINUS(差集),返回第一个查询检索出的记录减去第二个查询检索出的记录之后剩余的记录。
6.2 并集运算
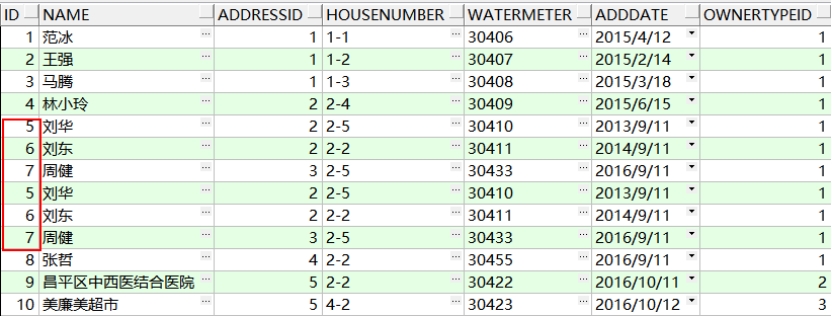
示例:UNION ALL 不去掉重复记录
1
2
3
SELECT * FROM t_owners WHERE id <=7
UNION ALL
SELECT * FROM t_owners WHERE id >=5
-
结果如下:
示例:UNION 去掉重复记录
1
2
3
SELECT * FROM t_owners WHERE id <=7
UNION
SELECT * FROM t_owners WHERE id >=5
-
结果如下:
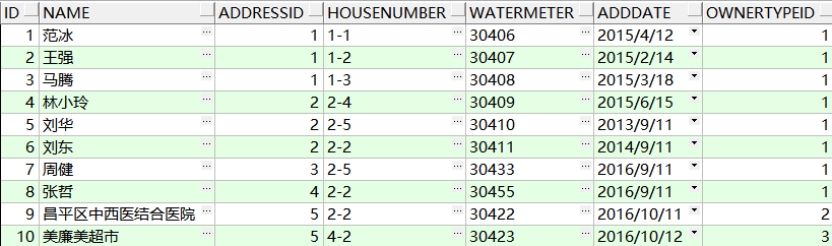
6.3 交集运算
示例:
1
2
3
SELECT * FROM t_owners WHERE id <=7
INTERSECT
SELECT * FROM t_owners WHERE id >=5
-
结果如下:

6.4 差集运算
示例:
1
2
3
4
-- 显示的是第1个结果集中有的但第2个结果集中没有的记录
SELECT * FROM t_owners WHERE id <=7
MINUS
SELECT * FROM t_owners WHERE id >=5
-
结果如下:

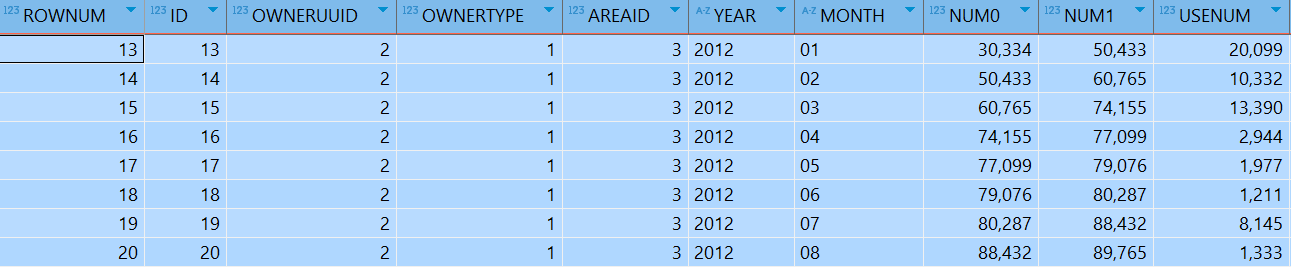
用minus运算符来实现分页,语句如下:
1
2
3
SELECT rownum,ac.* FROM t_account ac WHERE rownum <=20
MINUS
SELECT rownum,ac.* FROM t_account ac WHERE rownum <=10;
-
执行结果:
7. 行列转换
行列转换是 SQL 中非常重要的数据处理技巧,它能将 行数据转换为列格式(行转列)或 列数据转换为行格式(列转行)。
7.1 行转列
场景:将多行中的不同值变成多个列(例如:统计不同月份的数据)
方法1:CASE WHEN + 聚合函数
示例:统计每个区域不同类型业主的数量(将业主类型转换为列)
1
2
3
4
5
6
7
8
9
10
SELECT
a.name AS 区域,
-- 行转列核心:将不同 ownertypeid 转为列
SUM(CASE WHEN o.ownertypeid = 1 THEN 1 ELSE 0 END) AS 居民数量,
SUM(CASE WHEN o.ownertypeid = 2 THEN 1 ELSE 0 END) AS 商户数量,
SUM(CASE WHEN o.ownertypeid = 3 THEN 1 ELSE 0 END) AS 单位数量
FROM t_owners o
JOIN t_address ad ON o.addressid = ad.id
JOIN t_area a ON ad.areaid = a.id
GROUP BY a.name;
方法2:PIVOT 关键字(Oracle 11g+)
PIVOT函数是一个非常强大的工具,它允许用户将行数据转换为列数据,即将表中的多个行值按照某个字段进行分组,并将这些字段的值作为列标题,然后将另一个字段的值填充到相应的列中。
PIVOT的基本语法如下:
1
2
3
4
5
6
SELECT 列1, 列2, ...
FROM 表
PIVOT (
聚合函数(列名)
FOR 列名 IN (值1 AS 别名1, 值2 AS 别名2, ...)
)
- 列1, 列2, … :这些是PIVOT操作后要保留的非聚合列。
- 聚合函数 :用于对PIVOT操作中的数据进行聚合的函数,如:SUM、AVG、MAX、MIN、COUNT等。
- FOR 列名 IN (…) :指定要转换为列的字段以及该字段的哪些值应该成为新的列标题。
- 值1 AS 别名1, 值2 AS 别名2, … :这些是原始列中的值及其对应的列标题别名。
示例:统计每个区域的各月最大用水量
1
2
3
4
5
6
7
8
9
10
11
SELECT *
FROM (
SELECT ar.name AS area_name, ac.month, ac.usenum
FROM t_account ac
JOIN t_area ar ON ac.areaid = ar.id
)
PIVOT (
MAX(usenum)
FOR month
IN ('01' AS 一月, '02' AS 二月, '03' AS 三月)
);
行转列核心:
- 需要明确哪些值要变成新列(如月份、类型)
- 需要指定聚合规则(如 SUM、MAX)
7.2 列转行
场景:将多个列合并成一列(例如:将季度数据转为行)
方法1:UNION ALL 手动拼接
示例:将不同月份金额转为行
1
2
3
4
5
SELECT owneruuid, '一月' AS 月份, money AS 金额 FROM t_account WHERE MONTH='01'
UNION ALL
SELECT owneruuid, '二月', money FROM t_account WHERE MONTH='02'
UNION ALL
SELECT owneruuid, '三月', money FROM t_account WHERE MONTH='03';
方法2:UNPIVOT 关键字(Oracle 11g+)
UNPIVOT的基本语法如下:
1
2
3
4
5
6
7
8
9
10
11
12
SELECT *
FROM
(SELECT column1, column2, column3, ...
FROM table_name)
UNPIVOT (
value_column
FOR pivot_column IN (
column1 AS alias1,
column2 AS alias2,
...
)
);
value_column:是转换后行数据中值所在的列的名称。pivot_column:是转换后行数据中列标题(即原列名)所在的列的名称。IN子句中列出了需要被转换的列,以及它们转换后的别名。
示例:将每个月记录用水量的数据(num0、num1、usenum)转为行
1
2
3
4
5
6
7
8
9
10
SELECT owneruuid, month, 用水量说明,用水字数
FROM t_account
UNPIVOT (
用水字数
FOR 用水量说明 IN (
num0 AS '上个月用水量',
num1 AS '本月用水量',
usenum AS '实际用水量'
)
);
列转行核心:
- 需要定义新列的名称
- 需要指定要合并的原始列
7.3 练习示例
7.3.1 案例1 - 行转列
需求:将数据表中不同科目的成绩记录转换为列
-
原数据表内容:
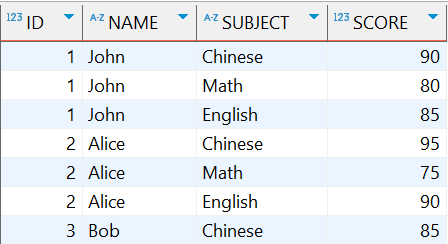
-
行转列后的结果:
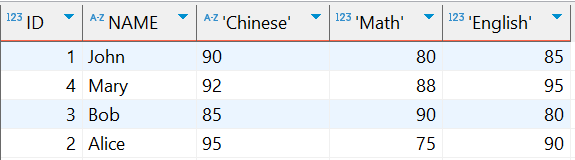
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
-- 表结构
CREATE TABLE scores (
id NUMBER,
name VARCHAR2(20),
subject VARCHAR2(20),
score NUMBER
);
-- 测试数据
INSERT INTO scores (id, name, subject, score) VALUES (1, 'John', 'Chinese', 90);
INSERT INTO scores (id, name, subject, score) VALUES (1, 'John', 'Math', 80);
INSERT INTO scores (id, name, subject, score) VALUES (1, 'John', 'English', 85);
INSERT INTO scores (id, name, subject, score) VALUES (2, 'Alice', 'Chinese', 95);
INSERT INTO scores (id, name, subject, score) VALUES (2, 'Alice', 'Math', 75);
INSERT INTO scores (id, name, subject, score) VALUES (2, 'Alice', 'English', 90);
INSERT INTO scores (id, name, subject, score) VALUES (3, 'Bob', 'Chinese', 85);
INSERT INTO scores (id, name, subject, score) VALUES (3, 'Bob', 'Math', 90);
INSERT INTO scores (id, name, subject, score) VALUES (3, 'Bob', 'English', 80);
INSERT INTO scores (id, name, subject, score) VALUES (4, 'Mary', 'Chinese', 92);
INSERT INTO scores (id, name, subject, score) VALUES (4, 'Mary', 'Math', 88);
INSERT INTO scores (id, name, subject, score) VALUES (4, 'Mary', 'English', 95);
SQL代码:
1
2
3
4
5
6
SELECT *
FROM (SELECT id, name, subject, score FROM scores)
PIVOT (
MAX(score)
FOR subject IN ('Chinese' AS 语文成绩, 'Math', 'English')
);
-
执行结果:
7.3.2 案例2 - 列转行
需求:将每位学生的课程及成绩,以行记录形式显示
-
原数据表内容
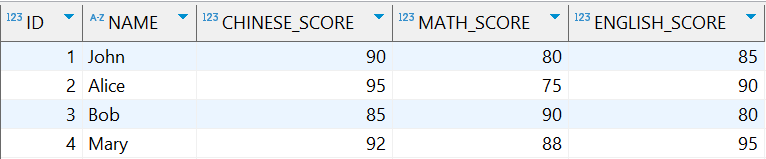
-
列转行后的结果:
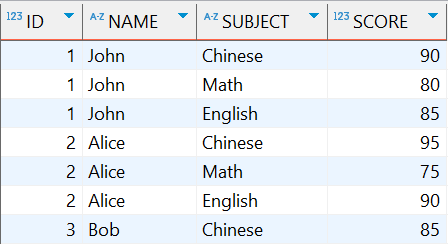
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- 表结构
CREATE TABLE scores (
id NUMBER,
name VARCHAR2(20),
chinese_score NUMBER,
math_score NUMBER,
english_score NUMBER
);
-- 测试数据
INSERT INTO scores (id, name, chinese_score, math_score, english_score) VALUES (1, 'John', 90, 80, 85);
INSERT INTO scores (id, name, chinese_score, math_score, english_score) VALUES (2, 'Alice', 95, 75, 90);
INSERT INTO scores (id, name, chinese_score, math_score, english_score) VALUES (3, 'Bob', 85, 90, 80);
INSERT INTO scores (id, name, chinese_score, math_score, english_score) VALUES (4, 'Mary', 92, 88, 95);
SQL代码:
1
2
3
4
5
6
7
8
9
10
SELECT id, name, subject, score
FROM scores
UNPIVOT (
score
FOR subject IN (
chinese_score AS 'Chinese',
math_score AS 'Math',
english_score AS 'English'
)
);
-
执行结果:
PIVOT和UNPIVOT的性能比手动写CASE WHEN或UNION ALL更高效,Oracle 会优化执行。
7.4 小结
行转列的优点:
1
2
结果更易读:行转列可以将多个字段合并到一行中,使结果更易读和理解。
适用于报表和展示:行转列通常更适用于报表和展示需求,可以提供更直观的结果。
行转列的缺点:
1
2
结构不灵活:行转列会将不同的字段合并到同一行中,这可能导致结果表的结构变得不灵活,不方便进行进一步的计算和分析。
数据冗余:行转列会导致数据冗余,因为多个字段的值被合并到同一行中,可能会产生冗余数据。
列转行的优点:
1
2
结构灵活:列转行可以将多个字段的值拆分成多行,结果表的结构更灵活,可以方便地进行进一步的计算和分析。
数据规范化:列转行可以将冗余的数据规范化,减少数据冗余。
列转行的缺点:
1
2
结果表较大:列转行可能会导致结果表的行数增加,结果表较大,可能会影响查询性能。
结果不易读:列转行后的结果可能变得不易读和理解,需要进一步的处理和解释。
总的来说,行转列和列转行各有各的应用场景和优缺点。在选择使用哪种方式时,需要根据具体的需求和数据特点来决定。
总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
/* 函数 */
-- 处理文本数据的函数
length(字段名 | '字符串')
replace(字段名, '被替换的字符串', "替换的字符串")
replace(字段名, '被替换的字符串') -- 替换功能变为了删除功能
substr(字段名 , 起始位置, 截取长度)
-- 处理日期数据的函数
add_months( 日期字段, 数值[添加多少个月] )
months_between(日期字段1, 日期字段2) -- 获取两个日期之间相差多少个月
trunc(日期字段, 'hh')
-- 处理数值数据的函数
round( numberF类型的字段 ) -- 四舍五入取整
round( number类型的字段 , 小数位数 ) -- 按照指定的小数位数,进行四舍五入
trunc( 数值数据 )
trunc( 数值数据 , 小数位数 ) -- 按照指定的小数位数,进行截断
-- 实现数据之间转换的函数
to_char(日期类型的数据, 'yyyy-mm-dd') -- 根据指定的格式,把日期数据转换为字符串
to_char(数值类型数据, '000,000,000') -- 根据指定的格式,把数值数据转换为字符串
to_date('日期格式字符串', 'yyyy/mm/dd') -- 把日期格式字符串转换为date类型数据
to_number('数字格式字符串') -- 把数字格式字符串为number类型数据
-- 空值处理函数
NVL(字段名, 缺省值 ) -- 当指定的字段下有NULL数据时,会默认使用指定的"缺省值"
NVL2(字段名, 不为null时的值, 为null时的值)
-- decode函数 : 提升SQL优化(减少读写数据文件的次数)
decode(字段名, 值1,翻译值1, 值2,翻译值2, ..... )
decode(gender, 'F',"女性", 'M',"男性" )
(case
gender
when 'F' then '女性'
when 'M' then '男性'
end) AS 别名
(case
when gender='F' then '女性'
when gender='M' then '男性'
end) AS 别名
/* 集合运算 */
union all 并集: 多个查询的结果合并在一起(重复行数据不去重)
union 并集: 多个查询的结果合并在一起(重复行数据去重)
intersect 交集: 仅保留多个查询的结果集中相同的数据
minus 差集: 仅保留第1个查询结果集独有的数据(第2个查询结果集中相同的数据会剔除)
/* 行列转换 */
-- 行转列
select .......
from 表名
pivot(
聚合函数(字段1)
for 字段2 in
(
数据1 AS 别名1(新列名1)
数据2 AS 别名2(新列名2)
....
)
)
-- 列转行
select ..... 新列名1,新列名2, ....
from 表名
unpivot(
字段名(新列名1)
for 新列名2 in
(
旧字段名1 as 数据1 (会填充到新列名2下面)
旧字段名2 as 数据2
.....
)
)
附录:编码表
编码表:把生活中的数据和计算机中的数据集成在一起,形成一个类似表格一样的东西。
- 好处:快速的把生活中的数据和计算机中的数据进行相互转换
| 生活中的数据 | 编码值(数字) | 计算机中的数据(仅参考) |
|---|---|---|
| 0 | 48 | 1010101010100101010 |
| a | 97 | 1010101001010101001 |
| A | 65 | 1110101010101011110 |