Oracle数据库中表的增删改查
1. 表的修改与删除
1.1 修改表
需求:业务发生了变更,业主信息缺失两个数据注销时间(outdate)和备注(remark)
-
分析需求:
- 需要给业主表
t_owners新增两个字段:outdate、remark - 确认
outdate和remark的数据类型
- 需要给业主表
修改表 - 增加字段的语法:
1
ALTER TABLE 表名称 ADD(列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...);
SQL代码:
1
2
3
4
5
6
--追加新字段
ALTER TABLE t_owners ADD
(
outdate DATE,
remark VARCHAR2(20)
);
需求:随着公司业务的推进,有一天发现向t_owners表新增数据时,数据新增失败,出现了报错信息。

- 分析报错原因:在向
remark字段下存储数据时,要存储的数据长度为33,而remark字段最大存储上限为20 - 解决方案:把
remark字段的存储上限设置提升为更大的存储空间
修改表 - 修改字段类型的语法:
1
ALTER TABLE 表名称 MODIFY (列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...);
SQL代码:
1
2
3
4
5
-- 修改字段
ALTER TABLE T_OWNERS MODIFY
(
REMARK VARCHAR2(200) -- 把存储上限从20调整到200
);
修改字段名语法:
1
ALTER TABLE 表名称 RENAME COLUMN 原列名 TO 新列名;
SQL示例:
1
ALTER TABLE T_OWNERS RENAME COLUMN OUTDATE TO EXITDATE;
删除字段名语法:
1
2
3
4
--删除一个字段
ALTER TABLE 表名称 DROP COLUMN 列名;
--删除多个字段
ALTER TABLE 表名称 DROP (列名1,列名2...);
SQL示例:
1
2
--删除字段
ALTER TABLE T_OWNERS DROP COLUMN REMARK;
小结:
-- 修改表:新增字段
ALTER TABLE 表名 ADD (字段名 数据类型, ....)
-- 修改表:修改字段类型
ALTER TABLE 表名 MODIFY (字段名 新数据类型, ....)
-- 修改表:修改字段名
ALTER TABLE 表名 RENAME COLUMN 旧字段名 TO 新字段名
-- 修改表:删除字段
ALTER TABLE 表名 DROP (字段名)
1.2 删除表
场景:在开发当某张数据表不需要时,会进行删除。
删除表的语法:
1
DROP TABLE 表名称
SQL示例:
1
DROP TABLE t_owners;
警示:
记住在开发中不是自己创建的表,不要删除(避免一些误删的情况发生)
删除表之间建议先进行备份(如果误删除了还可以还原)
1.3 SQL小结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
-- 创建表空间
create tablespace 表空间名 数据文件 初始化大小 自动扩容 扩容大小 文件最大上限
-- 修改表空间:新增数据文件
alter tablespace 表空间名 add datafile 数据文件 size 大小
-- 删除表空间:
drop tablespace 表空间
drop tablespace 表空间 including contents and datafiles
-- 创建用户:
create user 用户名 identified by 密码 default tablespace 表空间名
-- 修改用户密码
alter user 用户名 identified by 新密码
-- 修改用户默认表空间:
alter user 用户名 default tablespace 新的表空间名
-- 删除用户:
drop user 用户名
-- 用户授权:
系统权限:grant create session,create table,alter table to 用户
对象权限:grant select on 表名 to 用户名
grant select,insert on 用户1.表名 to 用户2
-- 创建表:
create table 表名(
字段名 数据类型(长度) [约束]
)tablespace 表空间
-- 修改表-新增字段:
alter table 表名 add (列名 数据类型 [约束] , ...)
-- 修改表-修改字段类型:
alter table 表名 modify (列名 数据类型 [约束] , ...)
-- 修改表-修改字段名称:
alter table 表名 rename column 旧字段 to 新字段
-- 修改表-删除字段:
alter table 表名 drop(字段名,…)
-- 删除表:
drop table 表名
2. 数据增删改
DML(Data Manipulation Language):数据操作语言,用来对数据表中的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
2.1 插入数据
插入一行记录的语法:
1
INSERT INTO 表名(列名1,列名2,...) VALUES (值1,值2,...);
示例:
1
2
3
4
5
6
-- 以下代码不推荐使用
insert into t_owners values (1,'范冰',1,'1-1',30406,sysdate,1 );
-- 推荐使用:
INSERT INTO t_owners(id,name,addressid,housenumber,watermeter,adddate,ownertypeid)
VALUES (2,'王强',1,'1-2',30407,sysdate,1);
插入多行记录的语法:发送一条数据库请求就能全部写入,效率高
1
2
3
4
5
6
7
8
9
10
-- 发送一条数据库请求就能全部写入,效率高
INSERT ALL
INTO 表名1(列名1,列名2,...) VALUES (值1,值2,...)
INTO 表名1(列名1,列名2,...) VALUES (值1,值2,...)
INTO 表名1(列名1,列名2,...) VALUES (值1,值2,...)
INTO 表名2(列名1,列名2,...) VALUES (值1,值2,...)
INTO 表名2(列名1,列名2,...) VALUES (值1,值2,...)
.......
INTO 表名N(列名1,列名2,...) VALUES (值1,值2,...)
SELECT * FROM dual;
示例:
1
2
3
4
5
6
INSERT ALL
into t_owners(ID,NAME,ADDRESSID,HOUSENUMBER ,WATERMETER,ADDDATE,OWNERTYPEID)
VALUES (2,'王强',1,'1-2',30407,to_date('2015-02-14','yyyy-MM-dd'),1 )
into t_owners(ID,NAME,ADDRESSID,HOUSENUMBER ,WATERMETER,ADDDATE,OWNERTYPEID)
VALUES (3,'马腾',1,'1-3',30408,to_date('2015-03-18','yyyy-MM-dd'),1 )
SELECT * FROM dual;
Oracle的dual表是一个特殊的单行单列虚拟表,但所有用户均可通过名称直接访问。其核心作用是满足SQL语法要求,在无需关联实际数据表的情况下执行查询操作。
2.2 修改数据
语法:
1
2
3
UPDATE 表名 SET 列名1=值1 ,列名2=值2 ,.... [WHERE 修改条件];
-- 说明:当update语句在执行时没有指定"修改条件",就会对表中指定列下的所有数据进行修改(全表修改)
示例:将ID为1的业主的登记日期更改为三天前的日期
1
UPDATE t_owners SET adddate=adddate-3 WHERE id=1;
2.3 删除数据
语法:
1
DELETE FROM 表名 [WHERE 删除条件];
示例:删除业主ID为2的业主信息
1
DELETE FROM T_OWNERS WHERE id=2;
删除表中所有数据:
1
TRUNCATE TABLE 表名称
比较truncate与delete实现数据删除?
- delete删除的数据可以rollback;truncate是不可回滚
- delete删除可能产生碎片,并且不释放空间;truncate不会产生碎片,会释放空间
- delete是逐条删除;truncate是先摧毁表,再重构表
3. 数据查询
数据查询需要使用到DQL(Data Query Language)语言,来查询数据表中的记录。
DQL查询语法结构如下:
SELECT DISTINCT
字段列表
FROM
表名
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
将上面的完整语法拆分为以下几个部分学习:
- 基本查询(不带任何条件)
- 去重查询(distinct)
- 条件查询(where)
- 分组查询(group by)
- 排序查询(order by)
3.1 基本查询
在基本查询的DQL语句中,不带任何的查询条件,语法如下:
-
查询多个字段
select 字段1, 字段2, 字段3 from 表名; -
查询所有字段(通配符)
-- 以下写法在开发中不推荐使用 select * from 表名; -
设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名; # as 可省略 别名不能用单引号
示例:查询所有业主信息
1
2
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners;
示例:查询所有业主的姓名、水表编号(给查询的字段添加别名)
1
2
SELECT name AS "姓名",watermeter "水表编号" -- 别名有空格就用双引号
FROM t_owners;
3.2 去重查询
1
SELECT DISTINCT 字段列表 FROM 表名
去重查询使用关键字:DISTINCT
示例:查询业主表中的地址ID,不重复显示
1
SELECT DISTINCT addressid FROM t_owners;
3.3 条件查询
学习条件查询就是学习条件的构建方式,而在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| != | 不等于 |
| between … and … | 在某个范围之内(含最小、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
| is not null | 不是null |
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| and | 并且 (多个条件同时成立) |
| or | 或者 (多个条件任意一个成立) |
| not | 非 , 不 |
1
2
3
4
5
6
SELECT [ DISTINCT ]
字段列表
FROM
表名列表
WHERE
条件列表
示例1:查询水表编号为30408的业主记录
1
2
3
4
5
6
7
8
/* 查询的数据和"业主"有关系
业主表: t_owners
要查询的业主数据有: 业主所有的数据
查询的条件要求: 水表编号为30408 (查询条件)
*/
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE watermeter=30408;
示例2:查询 id小于等于5 的业主信息
1
2
3
4
5
6
7
8
9
/*
查询数据和"业主"有关
业主表:t_owners
查询的业主数据有: 业主所有数据
查询条件: id <= 5
*/
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE id <= 5;
示例3:查询T_PRICETABLE表中MAXNUM为空的记录
1
2
3
SELECT id,price,ownertypeid,minnum,maxnum
FROM t_pricetable
WHERE maxnum IS NULL;
示例4:查询T_PRICETABLE表中MAXNUM不为空的记录
1
2
3
SELECT id,price,ownertypeid,minnum,maxnum
FROM t_pricetable
WHERE maxnum IS NOT NULL;
示例5:查询业主名称包含“刘”的业主记录
1
2
3
4
5
6
7
8
9
10
11
12
13
/* 模糊匹配: 查询条件中的数据和指定的数据只要有匹配度,就会查询匹配成功的数据
需要使用匹配符号: % _ ,来实现模糊
% 匹配任意字符(0个任意字符、多个任意字符)
_ 匹配一个任意字符
使用关键字:LIKE 和 模糊匹配符号 ,一起实现模糊查询
查找姓刘的用户数据: name LIKE '刘%'
查找邮箱中包含字母g的数据: email LIKE '%g%'
查找学生中姓名为两个字的学生: name LIKE '__'
*/
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE name like "%刘%";
示例6:查询业主名称包含“刘”的并且门牌号包含5的业主记录
1
2
3
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE name LIKE '%刘%' AND housenumber LIKE '%5%';
示例7:查询业主名称包含“刘”的或者门牌号包含5的业主记录
1
2
3
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE name LIKE '%刘%' OR housenumber LIKE '%5%';
示例8:查询业主名称包含“刘”的或者门牌号包含5的业主记录,并且地址编号为3的记录
1
2
3
SELECT id,name,addressid,housenumber,watermeter,adddate,ownertypeid
FROM t_owners
WHERE (name LIKE '%刘%' OR housenumber LIKE '%5%') AND (addressid = 3);
示例9:查询账单记录中用水字数(usenum字段)大于等于10000,并且小于等于20000的记录
1
2
3
4
5
6
7
8
9
10
-- 使用 >= 和 <= 符号 判断一个范围
SELECT *
FROM t_account
WHERE usenum>=10000 AND <=20000;
-- 使用关键字: between 起始值 and 截止值 取值一个范围
(包含起始值) (包含截止值)
SELECT *
FROM t_account
WHERE usenum BETWEEN 10000 AND 20000;
3.4 分组查询
3.4.1 聚合函数
之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
select 聚合函数(字段),聚合函数(字段2) from 表名 ;
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
count :按照列去统计有多少行数据。例:count(列名)
- 在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
count(*):*表示一整行数据,是按照整行数据进行统计(性能比较低)sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
max :计算指定列的最大值
min :计算指定列的最小值
avg :计算指定列的平均值
示例1:统计业主数量
1
2
3
4
-- ORACLE数据库中通常使用: count(主键列)、 count(1)
SELECT count(id) FROM t_owners;
SELECT COUNT(1) FROM t_owners;
示例2:统计2012年所有用户的用水量总和
1
2
3
SELECT sum(usenum) AS "用水量总和"
FROM t_account
WHERE YEAR='2012';
示例3:统计2012年所有用水量(字数)的平均值
1
2
3
SELECT avg(usenum)
FROM t_account
WHERE YEAR='2012';
示例4:统计2012年最高用水量
1
2
3
SELECT max(usenum)
FROM t_account
WHERE YEAR = '2012';
示例5:统计2012年最低用水量
1
2
3
SELECT min(usenum)
FROM t_account
WHERE YEAR = '2012';
3.4.2 分组聚合group by
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
1
2
3
4
5
6
7
8
9
10
SELECT DISTINCT
字段列表
FROM
表名
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
示例:按区域分组统计水费合计数
1
2
3
4
SELECT areaid , sum(money) AS total_money
FROM t_account
WHERE ISFEE='1'
GROUP BY areaid;
注意:
在SELECT 列表中所有未包含在聚合函数中的列都应该包含在 GROUP BY 子句中。
反之,包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
示例:查询水费合计大于169000的区域及水费合计
1
2
3
4
5
SELECT areaid , sum(money) AS total_money
FROM t_account
WHERE ISFEE='1' -- where条件中不能使用带有聚合函数的条件
GROUP BY areaid
HAVING sum(money)>169000;
注意事项:
HAVING子句不能离开GROUP BY子句单独使用,HAVING子句无法完全代替WHERE子句
在分组时使用Where子句和Having子句的本质区别:
使用having子句过滤,是先分组,再过滤,注意:分组的时候是全表扫描的,效率较低。
使用where子句过滤,是先过滤再分组,注意:分组的时候仅需要扫描部分数据,效率较高。
结论:
- 从语法上看,两者选择简单归纳为,就是group by分组之后需要的条件中有组函数的,就必须得用having,其他都可以直接用where
- 从性能上看,实际开发中,使用分组的时候尽量先加一个where的过滤条件。没有组函数的情况下,尽量选择where
3.5 排序查询
排序在日常开发中是非常常见的一个操作,排序方式有:
-
ASC :升序(默认值)
-
DESC:降序
1
2
SELECT 字段列表 FROM 表名 [WHERE 条件列表]
ORDER BY 排序字段1 排序方式 , 排序字段2 排序方式
1、升序排序
示例:对T_ACCOUNT表按使用量进行升序排序
1
SELECT * FROM t_account ORDER BY usenum ASC; -- 可以省略 ASC
查询结果:
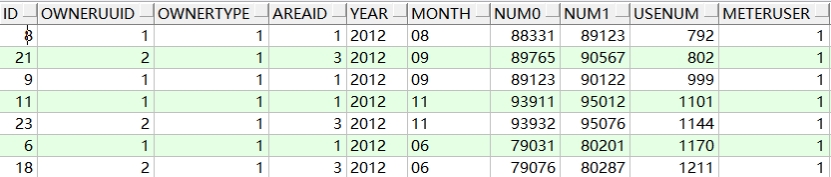
2、降序排序
示例:对T_ACCOUNT表按使用量进行降序排序
1
SELECT * FROM t_account ORDER BY usenum DESC;
查询结果:
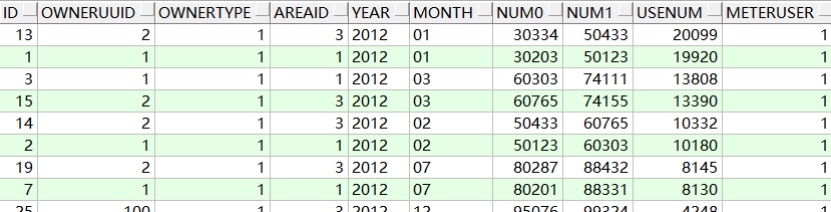
1
2
3
4
5
-- 对账户表进行查询,按照年份、月份、实际用水量进行排序
-- 排序要求:年-升序 月份-升序 用水量-降序
SELECT * FROM t_account
ORDER BY YEAR ASC , MONTH ASC , usenum DESC;
-- 多字段排序机制: 先按第1个字段排序,如果数据有相同则按第2个字段排序,如数据还有相同,按第3个字段排序
3.6 SELECT执行顺序
1
2
3
4
5
6
7
8
9
10
11
12
SELECT DISTINCT
字段列表
FROM
表名
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
在Oracle数据库中,SELECT语句的执行顺序并不是按照我们在SQL语句中编写的顺序执行的。实际上,Oracle数据库在执行SELECT查询时遵循一个特定的执行计划,这个计划决定了各个步骤的执行顺序。了解这个执行顺序对于优化查询性能和编写高效SQL语句至关重要。
Oracle中SELECT的执行顺序大致可以分为以下几个步骤:
-
FROM:首先,数据库从FROM子句中指定的表中读取数据。 -
WHERE:在从FROM子句获取数据后,数据库会根据WHERE子句的条件来过滤这些数据。这一步是在数据被读取之后立即进行的,因此可以显著减少需要处理的数据量。 -
GROUP BY:如果查询中包含GROUP BY子句,那么数据库将根据指定的列对数据进行分组。这一步是在WHERE子句过滤后的数据上进行的。 -
HAVING:在数据被分组后,HAVING子句会对分组后的结果进行过滤。这类似于WHERE子句,但它作用于GROUP BY的结果。 -
SELECT:在选择(SELECT)阶段,数据库会选择出需要显示的列。如果使用了聚合函数(如SUM, AVG等),这些函数也会在这一步被计算。 -
DISTINCT:如果查询中使用了DISTINCT关键字,那么在这一步会对结果进行去重。 -
ORDER BY:根据ORDER BY子句指定的列对结果进行排序。需要注意的是,排序操作是在最后进行的,这意味着前面的步骤已经处理好了大部分的数据,排序操作不会对性能产生太大影响